

Java 생태계에 올라간 강력한 AI 에이전트 통합 개발 방법

- 원제 : 이것이 Spring AI다 (개정판)
- 저자 : 신용권
- 출판 : 한빛미디어, 2026
“한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다.”
지난달에 LangChain 기반으로 AI 에이전트를 만드는 책을 읽었다. 체인 구성, RAG, 메모리, MCP, 종합 프로젝트까지 한 호흡으로 따라가면서 에이전트가 대강 어떤 구조로 돌아가는지 감을 잡을 수 있었다. 그런데 그 책은 Python이었다. 나는 Java 개발자다. 실무에서 Spring Boot와 Spring Framework를 매일 쓰고 있고, 솔직히 익숙한 생태계에서 AI를 다룰 수 있으면 그게 제일 좋다.
그래서 이 책이 반가웠다. ‘이것이 Spring AI다’는 Python을 거치지 않고, Spring Boot 프로젝트 안에서 바로 AI를 다루는 방법을 알려준다. 프롬프트 엔지니어링부터 멀티 에이전트 오케스트레이션까지 꽤 넓은 범위를 다루고 있다. 지난달에 Python으로 봤던 개념들이 Spring의 언어로 어떻게 번역되는지 비교하면서 읽으니 흡수 속도가 확실히 빨랐다.
익숙한 패턴이 AI를 만났을 때
이 책을 읽으면서 가장 먼저 든 생각은 “Spring 개발자가 쓰기 편하게 만들었구나”였다. ChatModel 인터페이스가 Model을 상속받고, AI 모델이 변경되더라도 애플리케이션 소스 변경이 최소화된다는 설계는 Spring의 인터페이스 기반 추상화 그대로다. VectorStore 인터페이스도 마찬가지다. 벡터 저장소가 PGVector에서 다른 것으로 바뀌어도 코드 변경이 최소화된다. 이게 새로운 기술인데도 불구하고 낯설지 않은 이유다.
특히 Advisor 개념이 눈에 띈다. Advisor는 애플리케이션과 LLM 사이의 상호작용을 가로채서, 프롬프트를 강화하거나 응답을 변환하는 구조인데, Spring AOP나 Servlet Filter를 떠올리면 바로 이해가 된다. 요청이 들어오면 AdvisorA 전처리, AdvisorB 전처리를 거쳐 LLM에 도달하고, 응답은 역순으로 후처리를 거쳐 돌아온다. 이 체인 구조 위에 대화 기억, RAG, 세이프가드 같은 기능이 전부 Advisor로 올라간다. 반복적인 전·후처리 로직을 캡슐화해서 재사용할 수 있다는 점은 Spring을 써본 사람이라면 자연스럽게 받아들일 수 있을 것이다.
개인적으로 이 부분이 LangChain과 비교할 때 Spring AI의 가장 큰 차별점이라고 생각한다. LangChain이 체인 개념으로 프롬프트-응답 단계를 연결한다면, Spring AI는 스프링 빈으로 자동 주입된 API로 메소드 호출 방식으로 처리한다. 사고방식 자체가 다르다. 그리고 ChatClient의 Fluent API 스타일 메소드 체이닝은 Spring 개발자한테 매우 익숙한 코딩 패턴이다.
차근차근 쌓아가는 구조
책의 구성이 단순 나열이 아니라 인과관계가 있다는 점이 마음에 들었다. 1부에서 텍스트 대화, 프롬프트 엔지니어링, 구조화된 출력, 음성, 비전, Advisor를 하나씩 쌓아가고, 2부에서 그것들을 합쳐서 임베딩, 대화 기억, RAG, 도구 호출, MCP, 에이전트, 멀티 에이전트를 구현한다. 뒤에서 등장하는 개념이 앞에서 배운 것 위에 올라간다.
예를 들어 RAG를 구현하려면 임베딩과 벡터 저장소를 알아야 하고, 대화 기억은 Advisor 체인 위에서 동작하고, 에이전트는 도구 호출과 대화 기억을 동시에 사용하고, 멀티 에이전트는 에이전트를 도구로 만들어서 오케스트레이터가 호출한다. 이 빌드업이 잘 되어 있어서, 중간에 챕터를 건너뛰면 이후 내용이 이해가 안 될 수 있다.
프롬프트 엔지니어링 챕터에서 6가지 기법을 Spring AI 코드로 보여준다. 제로-샷은 예시 없이 바로 작업을 요청하는 방식이고, 퓨-샷은 몇 개의 예시를 제공해서 원하는 출력 형식을 학습시키는 방식이다. 역할 부여는 LLM에게 “당신은 경험이 풍부한 데이터 과학자입니다” 같은 정체성을 부여해서 출력의 톤과 깊이를 조정한다. 스텝-백은 복잡한 질문을 여러 단계로 분해해서 배경 지식을 확보하는 기법이고, 생각의 사슬은 “한 걸음씩 생각해 봅시다”라는 한 문장으로 LLM의 중간 추론 단계를 유도한다. 자기 일관성은 같은 질문을 여러 번 보내서 다수결로 최종 답을 정하는 방식이다.
평소에 AI를 다루면서 “역할을 지정하면 답변이 더 좋아진다”거나 “질문을 단계별로 나누면 낫다” 같은 건 경험적으로 알고 있었는데, 이것들에 정식 명칭이 있다는 건 이 책에서 처음 알았다. 특히 스텝-백 프롬프트가 인상적이었는데, 사용자 질문을 LLM에게 보내서 하위 질문 목록을 JSON 배열로 받고, 각 답변을 context에 누적시키면서 다음 단계로 넘기는 구조다.
public String getStepAnswer(String question, String... prevStepAnswers) {
String context = "";
for (String prevStepAnswer : prevStepAnswers) {
context += Objects.requireNonNullElse(prevStepAnswer, "");
}
String answer = chatClient.prompt()
.user("""
%s
문맥: %s
""".formatted(question, context))
.call()
.content();
return answer;
}
이전 단계 답변들이 다음 단계의 문맥이 되는 구조라서, 복잡한 질문을 분해할 때 바로 쓸 수 있겠다 싶었다.
자기 일관성도 코드로 보면 단순한데, temperature를 1.0으로 올려서 5번 응답을 받고 다수결로 최종 분류를 결정한다.
for (int i = 0; i < 5; i++) {
String output = chatClient.prompt()
.user(userText)
.options(ChatOptions.builder()
.temperature(1.0)
.build())
.call()
.content();
if (output.equals("IMPORTANT")) {
importantCount++;
} else {
notImportantCount++;
}
}
String finalClassification = importantCount > notImportantCount ?
"중요함" : "중요하지 않음";
단순하지만 안정성이 필요한 분류 작업에서 써먹을 만하다. 이런 식으로 개념만 설명하지 않고 Spring AI 코드로 직접 보여주니까 따라가기가 편했다.
RAG 모듈화가 깔끔하다
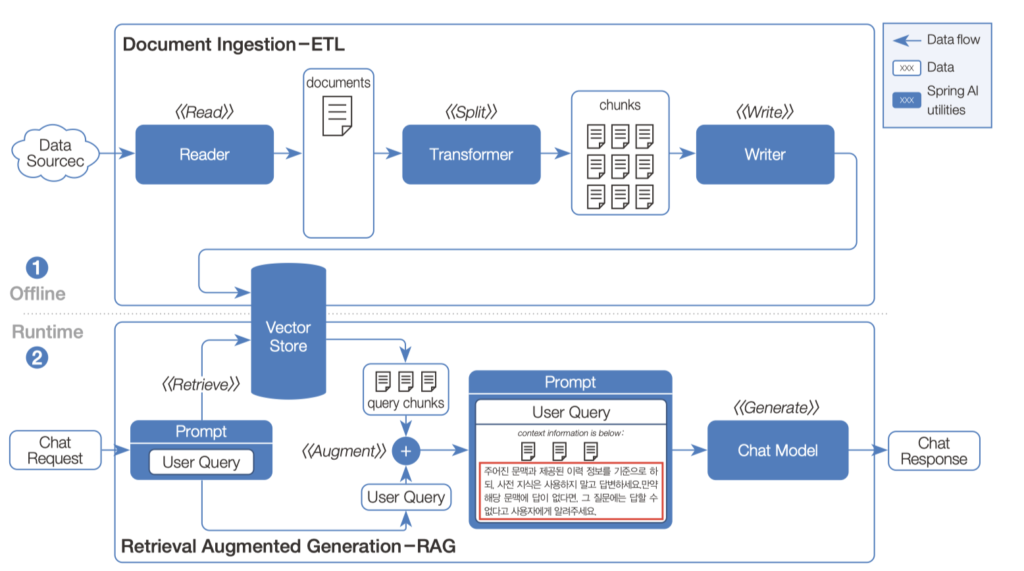
RAG 파트는 이 책에서 가장 실무적으로 와닿는 부분이다. QuestionAnswerAdvisor가 기본적인 RAG를 제공하지만, RetrievalAugmentationAdvisor는 검색 전, 검색, 검색 후, 생성 네 단계를 독립 모듈로 나눠서 필요한 것만 조합할 수 있게 만들었다.
검색 전 모듈이 특히 흥미로웠다. CompressionQueryTransformer는 “아까 그거”같은 모호한 질문을 LLM으로 완전한 질문으로 변환해주고, RewriteQueryTransformer는 장황한 질문을 재작성해서 검색 품질을 높인다. TranslationQueryTransformer는 사용자 질문을 임베딩 모델이 지원하는 언어로 번역한다. MultiQueryExpander는 하나의 질문을 여러 관점의 확장 질문으로 만들어서 검색 적중률을 올린다.
이 모듈들이 독립적이라는 게 핵심이다. 다국어 서비스면 TranslationQueryTransformer를 끼우고, 대화형 RAG면 CompressionQueryTransformer를 추가하면 된다. 전부 다 쓸 필요도 없고, 상황에 맞게 골라 쓸 수 있다. 이 설계가 깔끔하다고 느꼈다.
여러 에이전트를 다루는 기술
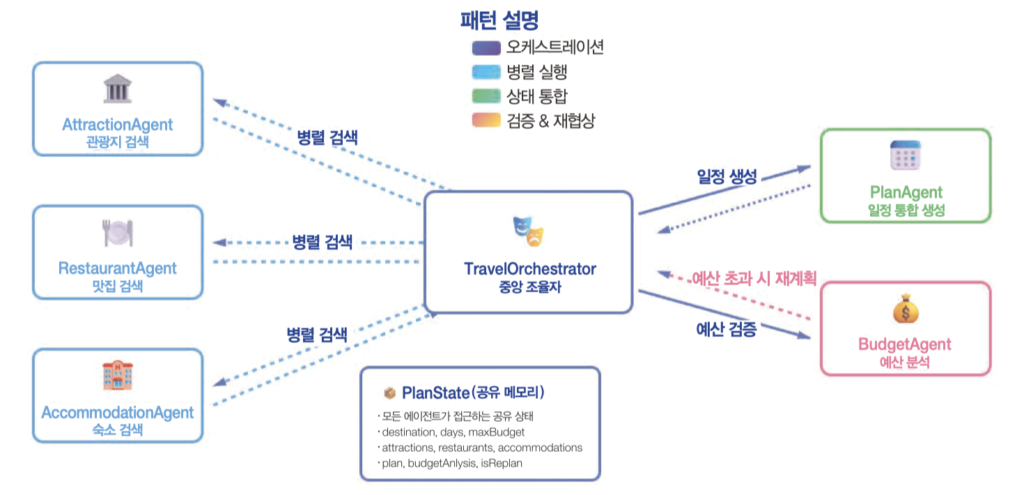
14장이 이 책의 클라이맥스다. 읽으면서 가장 많은 형광펜을 쳤던 챕터이기도 하다. 싱글 에이전트에 모든 역할을 몰아넣으면 어떤 문제가 생기는지부터 설명한다. “제주도 2박 3일 여행 일정을 만들어줘”라는 요청 하나에 관광지 선정, 맛집 추천, 숙소 선택, 일정 통합이 동시에 필요한데, 이걸 하나의 에이전트가 다 하면 프롬프트가 비대해지고, 도구 선택 규칙이 복잡해지고, 서로 다른 판단 기준이 LLM 내부에서 뒤섞인다. 결국 판단 품질이 떨어지거나 새 역할 추가 시 기존 로직이 깨지는 문제가 생긴다.
해결책은 역할이 분리된 멀티 에이전트 시스템이다. 각 에이전트는 자기 역할 범위 안에서만 판단하고, 다른 에이전트의 내부를 알 필요가 없다. 여기서 에이전트들을 조율하는 상위 구성 요소가 오케스트레이터다.
오케스트레이터와 Agents as Tools
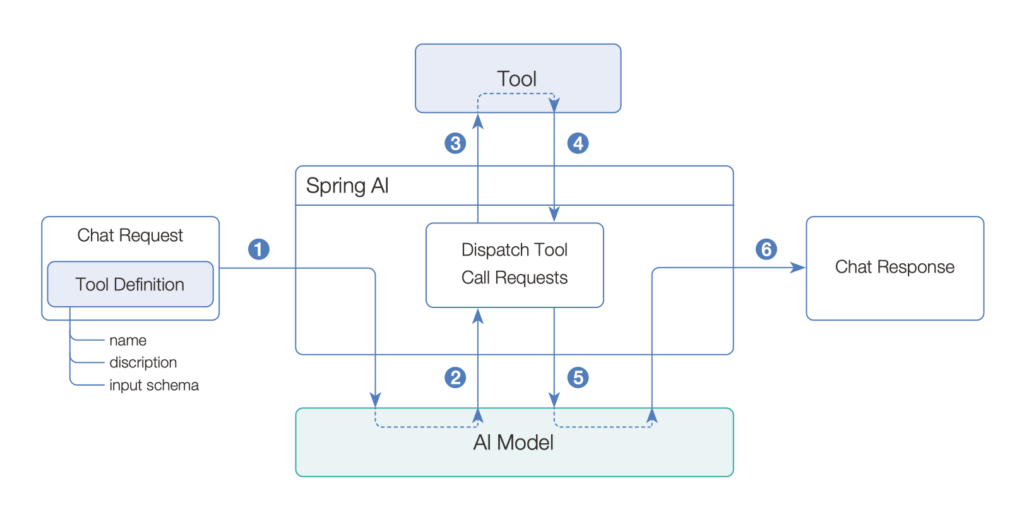
오케스트레이터 구현의 핵심 패턴인 ‘Agents as Tools’가 인상 깊었다. 하위 에이전트들을 각각 하나의 도구로 취급하고, LLM이 질문의 복잡도에 따라 어떤 도구를 호출할지 결정한다. @Tool 어노테이션이 붙은 메소드가 에이전트를 실행시키는 역할을 하기 때문에, 도구를 호출한다는 건 곧 에이전트를 실행하는 것과 같다.
@Tool(description = "관광지 정보를 조회합니다. ...", returnDirect = true)
public List<Attraction> callAttractionAgent(String query) {
List<Attraction> attractions = attractionAgent.execute(query);
return attractions;
}
returnDirect = true가 핵심이다. 오케스트레이터는 에이전트로 분기만 하고 실제 처리는 에이전트가 하므로, 에이전트의 결과를 다시 LLM으로 보낼 필요가 없다.
오케스트레이터의 실행 진입점을 보면 구조가 한눈에 들어온다. ChatClient를 빌드하고, 시스템 메시지로 사용 가능한 에이전트 목록과 호출 규칙을 정의하고, tools(this)로 현재 클래스의 모든 @Tool 메소드를 LLM에 노출시킨다.
String response = chatClient.prompt()
.system(systemMessage)
.user(userQuery)
.advisors(MessageChatMemoryAdvisor.builder(chatMemory).build())
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, conversationId))
.tools(this)
.call()
.content();
공유 상태와 워크플로우
여러 에이전트가 협업할 때 중간 결과물을 어떻게 공유하느냐가 중요하다. 이 책에서는 PlanState라는 공유 상태 객체를 정의한다. 요구사항, 에이전트별 결과, 예산 분석, 최종 일정, 재계획 플래그까지 전체 워크플로우의 상태가 하나의 객체에 담긴다.
@Data
public class PlanState {
private String destination;
private Integer days;
private Integer maxBudget;
private List<Attraction> attractions;
private List<Restaurant> restaurants;
private List<Accommodation> accommodations;
private BudgetAnalysis budgetAnalysis;
private Plan plan;
private Boolean isReplan;
private Integer previousTotalCost;
}
각 에이전트는 PlanState를 매개값으로 받아서, 자기 결과를 직접 저장한다. 오케스트레이터가 별도로 반환값을 관리할 필요가 없어지고, 다음 순서 에이전트는 이전 에이전트가 채워넣은 데이터를 바로 참조할 수 있다. 재계획이 필요한 경우에는 state.isReplan() 플래그를 보고 검색 쿼리를 동적으로 바꾼다. 예를 들어 숙소 에이전트는 재계획일 때 “가성비 저렴한 숙소 추천”으로 쿼리를 변경한다.
에이전트 병렬 실행과 동시성 처리
여기가 특히 좋았던 부분이다. 관광지, 맛집, 숙소 검색은 서로 독립적인 작업이라 순차 실행하면 시간 낭비다. 각각 2초씩 걸리면 최소 6초를 기다려야 하는데, 병렬로 돌리면 가장 오래 걸리는 에이전트 시간 하나로 줄어든다.
Spring AI에서 이걸 CompletableFuture로 처리하는 코드가 나온다.
private void collectTravelInfoInParallel(PlanState state) {
final SseEmitter emitter = threadLocal.get();
CompletableFuture<Void> attractionFuture = CompletableFuture.runAsync(() -> {
threadLocal.set(emitter);
sendSseEvent("AttractionAgent", "running", "관광지 검색 중...");
attractionAgent.execute(state);
sendSseEvent("AttractionAgent", "complete", "관광지 검색 완료");
});
CompletableFuture<Void> restaurantFuture = CompletableFuture.runAsync(() -> {
threadLocal.set(emitter);
sendSseEvent("RestaurantAgent", "running", "맛집 검색 중...");
restaurantAgent.execute(state);
sendSseEvent("RestaurantAgent", "complete", "맛집 검색 완료");
});
CompletableFuture<Void> accommodationFuture = CompletableFuture.runAsync(() -> {
threadLocal.set(emitter);
sendSseEvent("AccommodationAgent", "running", "숙소 검색 중...");
accommodationAgent.execute(state);
sendSseEvent("AccommodationAgent", "complete", "숙소 검색 완료");
});
CompletableFuture.allOf(attractionFuture, restaurantFuture, accommodationFuture)
.join();
}
runAsync()로 각 에이전트를 워커 스레드에서 독립 실행하고, allOf(...).join()으로 전부 끝날 때까지 대기한 다음 다음 단계로 넘어간다. InheritableThreadLocal을 써서 비동기 자식 스레드에도 SseEmitter를 공유하는 방식이 실무적이다.
실제로 오케스트레이터에서 이 병렬 수집 메소드를 호출하는 부분은 이렇게 생겼다.
@Tool(description = "새로운 전체 여행 일정을 생성합니다. ...", returnDirect = true)
public Plan callMultiAgentForTravelPlan(String userQuery) {
PlanState state = parseUserQuery(userQuery);
// 관광지/맛집/숙소를 병렬로 수집
collectTravelInfoInParallel(state);
// 수집된 정보로 일정 생성
plannerAgent.execute(state);
// 예산 검증
budgetAgent.execute(state);
// 예산 초과 시 재계획
if (state.getBudgetAnalysis().isExceeded()) {
replanWithAdjustedBudget(state);
}
return state.getPlan();
}
병렬 수집이 끝나야 일정 생성으로 넘어가고, 일정 생성이 끝나야 예산 검증으로 넘어가는 흐름이 코드에 그대로 드러난다. 병렬로 돌릴 수 있는 건 병렬로 돌리고, 순서가 필요한 건 순차로 두는 구조가 읽기 편하다.
자기 보정과 재계획 루프
PlanAgent가 일정을 만들면 BudgetAgent가 자바 코드로 예산을 검증한다. LLM은 창의적인 일정은 잘 짜지만 산술 연산에서 오차가 날 수 있기 때문에, 예산 계산은 LLM에 맡기지 않고 자바의 수치 계산으로 처리한다. 예산이 초과되면 오케스트레이터가 replanWithAdjustedBudget()을 호출해서 관광지, 맛집, 숙소를 다시 검색하고 일정을 재작성한다.
재계획 시 PlanAgent는 상태 객체의 재계획 플래그와 이전 비용을 읽어서 프롬프트를 동적으로 바꾼다. “이전 일정이 예산을 X원 초과했으니 더 저렴한 옵션을 선택하라”는 구체적인 지침이 프롬프트에 들어간다. 에이전트가 상태 정보를 바탕으로 스스로 프롬프트를 최적화하는 구조라서, 오케스트레이터가 복잡한 명령을 일일이 내리지 않아도 된다.
통제된 오케스트레이션과 멀티 LLM
이 책이 제안하는 오케스트레이션 방식은 ‘통제된 오케스트레이션’이다. LLM이 실행 순서를 즉흥적으로 결정하는 동적 플래닝이나, 에이전트들이 지휘자 없이 자유롭게 목표를 찾아가는 자율적 협업과는 다르다. 실행할 에이전트의 종류와 순서가 코드로 작성되어 있다. 자율형이 더 유연해 보일 수 있지만, 실제 비즈니스에서는 불필요한 루프, 토큰 낭비, 일관성 부족, 디버깅 어려움 같은 현실적 제약에 부딪힌다. 통제된 방식이면 PlanState를 통해 어디서 문제가 생겼는지 명확히 추적할 수 있다.
멀티 LLM 전략도 현실적이다. 모든 에이전트가 같은 모델을 쓸 필요가 없다. @Qualifier로 에이전트마다 다른 ChatClient.Builder를 주입받으면 된다.
// 숙소 에이전트는 Google Gemini 사용
public AccommodationAgent(
@Qualifier("geminiBuilder") ChatClient.Builder chatClientBuilder,
InternetSearchService searchService) { ... }
// 관광지 에이전트는 로컬 Llama 사용
public AttractionAgent(
@Qualifier("ollamaBuilder") ChatClient.Builder chatClientBuilder,
InternetSearchService searchService) { ... }
보안이 중요한 에이전트는 온프레미스 모델로, 창의적 생성이 필요한 에이전트는 고성능 클라우드 모델로 구성하는 식이다. Spring의 의존성 주입이 이런 식으로 활용되는 걸 보면 Spring AI가 단순히 AI API를 감싼 래퍼가 아니라 Spring 생태계의 강점을 제대로 활용하고 있다는 걸 느낀다.
아쉬운 부분
좋은 점이 많지만 아쉬운 부분도 있다. 책이 Spring AI 프레임워크의 기능을 순서대로 소개하는 구조라서, 각 챕터가 “이 API는 이렇게 쓴다”는 설명에 상당 부분을 할애한다. API 사용법은 공식 문서에서도 확인할 수 있으니, 그 지면을 실무 시나리오나 트러블슈팅에 더 할애했으면 어땠을까 하는 생각이 든다.
그리고 테스트에 대한 내용이 거의 없다. AI 기능을 포함한 애플리케이션을 어떻게 테스트할 것인가는 실무에서 상당히 중요한 주제인데, LLM 응답의 불확정성 때문에 기존 유닛 테스트 방식으로는 한계가 있다. 이 부분에 대한 가이드가 있었으면 했다.
누구에게 추천하는가
Java와 Spring Boot로 개발하고 있으면서 AI 기능을 서비스에 붙여야 하는 개발자에게 추천한다. Python을 거치지 않고 익숙한 Spring 생태계 안에서 AI를 다루고 싶다면 이 책이 현재로서는 가장 체계적인 가이드다.
다만 Spring Boot에 대한 기본 이해가 전제되어야 한다. 의존성 주입, REST Controller, 어노테이션 기반 설정 같은 것들이 익숙하지 않으면 AI 내용 이전에 Spring 문법에서 막힐 수 있다. AI 자체에 대한 이론적 깊이를 기대하는 사람에게는 다소 가벼울 수 있는데, 이 책은 AI 이론서가 아니라 Spring AI 프레임워크 실습서에 가깝기 때문이다.
개인적으로는 Advisor 체인 패턴과 RAG 모듈화, 그리고 멀티 에이전트의 Agents as Tools 패턴이 가장 인상 깊었다. 특히 최근 MCP 기반으로 외부 도구를 연결하는 작업을 하고 있었는데, 이 책의 12장에서 STDIO와 SSE 두 가지 통신 방식을 Spring AI로 구현하는 과정이 실무에 바로 참고가 됐다.
“한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다.”