

AI 에이전트 A to Z

- 원제 : AI 에이전트 마스터 클래스
- 저자 : 김구현
- 출판 : 한빛미디어, 2026
“한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다.”
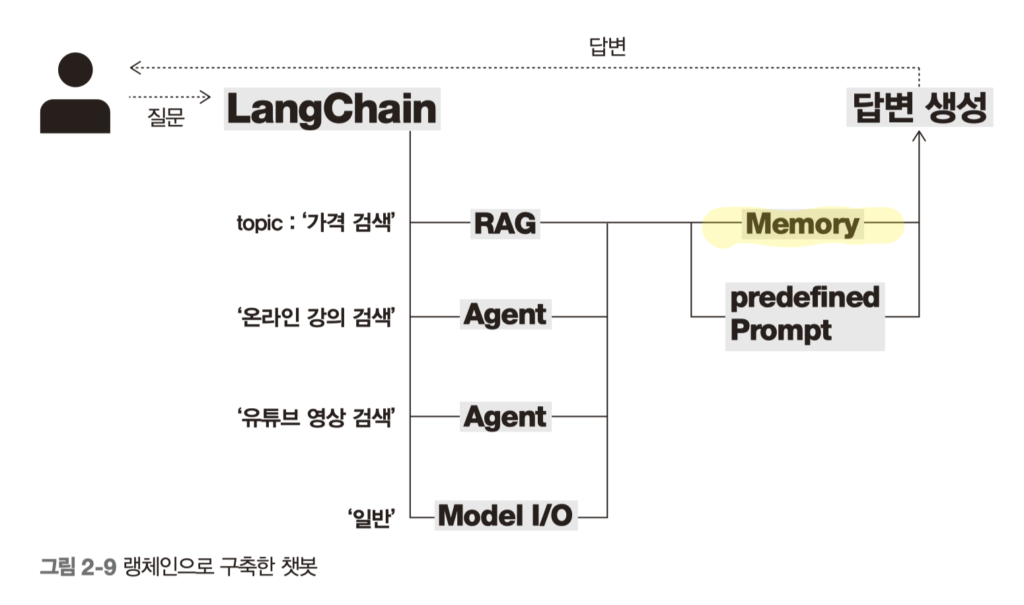
나는 백엔드 개발자로 활동하고 있지만, AI 시대에 힘입어 최근 이와 관련된 개발을 많이 하고 있다. 가장 최근에는 OpenStack MCP Server 에 참여했었고 그 외에 사내에서 AI 에이전트와 관련된 업무를 수행하고 있다. AI 와 관련된 개발을 하다보면 제공하는 입장에서 매번 답변이 다르고, 품질을 제어하기 힘들며, 어떻게 작동하는지 디버깅하기 어려운 부분들이 있었는데. 이번에 이 책을 읽으면서 그동안 쌓아둔 경험들을 쭉 정리할 수 있어서 도움이 되었다. 생각보다 많은 내용을 다루고 있어 에이전트, RAG, MCP 등 관련 업무를 해보지 않았으면 다소 난이도가 있을 수 있지만, 책에서 플레이그라운드 환경이나 로컬에서 가장 쉽게 실행해볼 수 있는 환경으로 How to 를 제공 하고 있다. 그렇기 때문에 목적을 두고 있으며, 일반적인 백엔드 상식이 있는 개발자라면 빠르게 읽고 실전 개발에 도움을 주는 책이 되겠다.
좋은 답변보다 좋은 흐름
이 책의 장점은 “도구를 많이 소개한다”가 아니라, 왜 에이전트 개발이 생각보다 어렵고 어디서 품질이 깨지는지를 순서대로 보여준다는 점이다. 초반에는 환경 설정과 기본 체인을 다루지만, 읽다 보면 관심이 자연스럽게 모델 성능에서 시스템 설계로 옮겨간다. 특히 PoC에서 PoV로 넘어가는 구간을 강조한 대목이 인상적이었다. 실제로 사내에서 AI 기능을 붙일 때도 데모 단계에서는 그럴듯하게 보이는데, 운영 데이터를 붙이는 순간 답변 신뢰도, 지연시간, 권한 정책, 실패 복구 같은 현실적인 문제가 연달아 나온다. 이 책은 그 간극을 “모델을 더 큰 걸 쓰면 된다”로 덮지 않고, 체인 구성과 데이터 흐름, 상태 관리 관점에서 풀어낸다.
LangChain, LangGraph 구간은 특히 백엔드 개발자에게 익숙한 언어로 읽힌다. LCEL을 설명하는 흐름은 결국 파이프라인 설계 이야기다. 프롬프트-모델-파서의 순서, 중간 산출물 보존, 병렬 분기, 라우팅 같은 패턴이 왜 중요한지 예시와 함께 보여준다. 여기서 얻은 가장 큰 인사이트는 “좋은 응답은 단일 호출에서 나오지 않는다” 는 점이었다. 입력을 정제하고, 필요한 문맥만 주입하고, 출력 구조를 검증 가능한 형태로 바꾸고, 실패 시 다음 경로를 준비해야 서비스 품질이 안정된다. 책에서 Runnable 인터페이스를 중심으로 이 과정을 일관되게 설명하는 방식이 좋았고, 설명이 비교적 짧은 코드 단위로 이어져 따라가기도 수월했다.
기억과 검색은 기능이 아니라 운영 정책
개인적으로 가장 공감한 부분은 메모리와 RAG 파트였다. 대화형 에이전트의 불만은 대부분 “말은 잘하는데 맥락을 잊는다” 에서 시작된다. 책은 이를 단순 기능 부족으로 보지 않고, 저장 정책 문제로 해석한다. 어떤 턴을 기억할지, 사용자별로 어떻게 분리할지, 긴 대화에서 무엇을 요약하고 무엇을 남길지 같은 기준이 없으면 모델 성능이 좋아도 사용자는 불안해진다. 이건 내가 실제 업무에서 겪은 문제와 거의 동일했다. 답변이 한번 좋게 나오는 것보다, 다섯 번째 질문에서도 같은 기준으로 답하는 것이 훨씬 어렵다.
RAG도 비슷하다. 요즘은 RAG를 붙이는 것 자체가 목표처럼 소비되는 경우가 많은데, 이 책은 검색 전략의 디테일을 계속 강조한다. 청킹 크기와 오버랩, 메타데이터 필터, Top-k, MMR 같은 요소를 조정하지 않으면 결국 찾긴 찾았는데 엉뚱한 답 이 나온다. 특히 사내 문서처럼 형식이 제각각이고 갱신 주기가 다른 데이터에서는 벡터 검색만으로 끝나지 않는다. 문서 타입, 작성 시점, 소유 팀 같은 필터를 먼저 걸어야 검색 품질이 안정된다. 이 부분을 실습 흐름으로 보여준 점은 실무 적용에 도움이 컸다. 모델 프롬프트를 잘 쓰는 능력과 검색 설계를 잘하는 능력이 별개라는 점을 분명히 짚어준다.
손으로 쌓아야 보이는 것들
이 책이 좋은 이유는 개념을 설명하고 끝내지 않고, 실제로 무엇을 만들어야 하는지 손에 잡히게 끌고 간다는 점이다. 시작부터 Python 3.11 기준으로 개발 환경을 맞추고, VS Code와 Google Colab을 이중 트랙으로 제시해 로컬 개발과 빠른 실험을 병행하게 만든다. OpenAI API 키와 LangSmith 키를 붙여 관측까지 열어두는 흐름도 실무 감각에 가깝다.
기술 스택도 LangChain, LCEL에서 시작해 Streamlit, LangGraph, FastMCP로 이어지는데, 단순 체인에서 라우팅 챗봇으로, 다시 도구를 쓰는 에이전트와 RAG 에이전트, MCP 서버, 마지막 종합 프로젝트까지 계단식으로 난이도를 올린다. 코드 중심 실습이라 손이 바쁘지만 맥락은 선명하다.
처음엔 openai.chat.completions.create() 한 줄로도 답이 나오지만, 검색 결과와 출처, 맥락, 시각화를 한 번에 묶으려니 조립 기준이 필요해졌고 그 지점에서 LangChain이 LLM 기반 서비스를 위한 프레임워크 로 등장한다. 체인을 사슬처럼 엮는 구조를 받아들이는 순간부터 구현이 빨라졌다.
chain = prompt | model | output_parser
result = chain.invoke({"topic": "AI 에이전트"})
invoke는 요청-응답 계약을 명확히 고정하고 stream은 실시간 피드백을 연출하는 역할로 갈린다. 순서를 prompt → model → output_parser로 지키지 않으면 ValueError가 나는 규칙 덕분에 체인 조립 실수를 초반에 잡아낸다. 결합 체인으로 한 번의 호출에 여러 단계를 순차 실행하는 흐름도 바로 붙고, 대화형 입력을 다룰 때는 ChatPromptTemplate 로 사용자 메시지와 AI 메시지를 분리해 맥락을 주입하는 방식이 안정적이었다.
여기서 출력 파서는 보기 좋은 포맷터가 아니라 다음 체인의 입력을 예측 가능하게 만드는 장치로 바뀌고, JsonOutputParser 만으로 구조가 흔들릴 때 pydantic 검증 계층을 추가해야 하는 이유가 선명해진다.
from pydantic import BaseModel
class AnswerSchema(BaseModel):
answer: str
source: str
parser = JsonOutputParser(pydantic_object=AnswerSchema)
chain = prompt | model | parser
사용자의 게으른 프롬프트를 그대로 넣으면 성능이 내려앉는 문제를 만나고, 질문 품질을 먼저 끌어올리는 전처리 체인을 둬야 다음 생성 품질이 안정됐다. 여기서 질문 정제 체인을 먼저 통과시킨 뒤 본 생성 체인으로 넘기는 구성이 실전 응답 품질을 가장 크게 끌어올렸다.
답변과 추천 질문을 동시에 만들어야 하는 순간엔 단일 체인이 병목이 되어 병렬 실행으로 확장했고, 두 결과를 한 번에 조합하는 구조가 실전에서 훨씬 쓸모가 컸다.
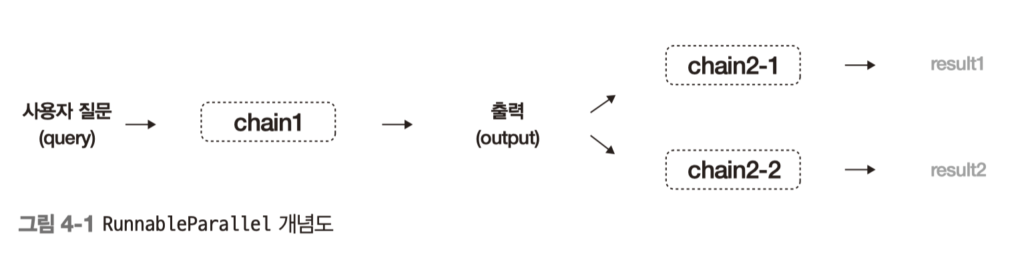
parallel_chain = RunnableParallel(
answer=answer_chain,
recommended_questions=recommend_chain,
)
질문 주제에 따라 수학, 과학, 기타 체인으로 나눠야 할 때는 분류 결과를 기준으로 라우팅 함수가 필요해졌고, RunnableLambda 를 중간에 꽂아 분기 로직을 분리하니 유지보수가 편해졌다.
def route(info):
topic = info["topic"]
if topic == "수학":
return math_chain
elif topic == "과학":
return science_chain
return general_chain
full_chain = classifier_chain | RunnableLambda(route)
Runnable 데이터는 딕셔너리로 흘러가며 단계마다 발전하고, 중간에 원본 입력을 잃지 않으려면 RunnablePassthrough.assign 으로 키를 확장하는 패턴이 안전했다.
chain = (
RunnablePassthrough.assign(context=retriever) |
prompt |
model |
parser
)
이후엔 두 번째 질문부터 맥락이 끊기는 문제를 만나서 대화 히스토리를 저장하고, 프롬프트 안에는 MessagesPlaceholder 로 주입 지점을 먼저 선언해 길이 변화에 버티는 구조로 바꿨다.
prompt = ChatPromptTemplate.from_messages([
("system", "당신은 AI 비서입니다."),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{question}"),
])
수동으로 저장하고 불러오던 흐름은 누락이 잦아서 결국 체인 바깥 자동 관리로 옮겼고, 세션 식별자 기반 분리가 없으면 사용자 맥락이 섞이는 사고가 바로 난다는 것도 초반에 확인했다.
chain_with_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="question",
history_messages_key="history",
)
체인이 안정되면 다음 병목은 인터페이스다. 터미널 출력만으로는 사용자 피드백을 받기 어려워 Streamlit으로 넘어가고, 질문 의도를 먼저 분류한 뒤 토픽별 체인으로 2단계 라우팅을 걸어야 답변 일관성이 유지됐다.
classify_chain = prompt_classify | model | StrOutputParser()
full_chain = (
RunnablePassthrough.assign(topic=classify_chain) |
RunnableLambda(route_by_topic)
)
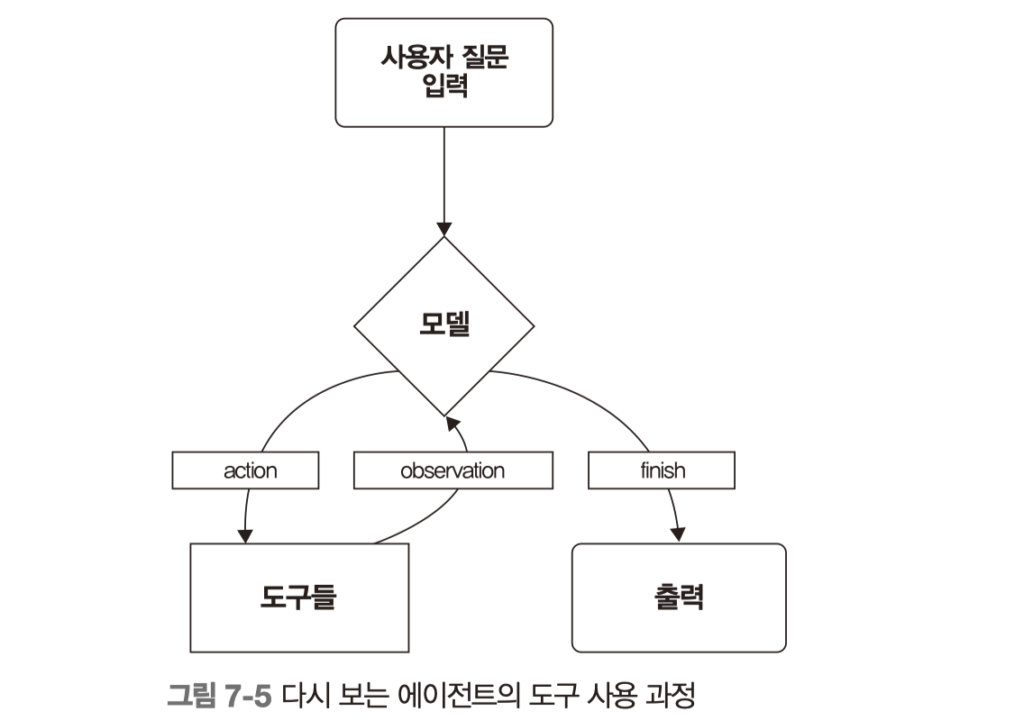
그래도 “내일 오전 10시 서울 날씨” 같은 질문을 만나면 답변 생성만으로는 해결이 안 되고, 외부 API를 붙인 도구 호출과 ReAct 루프의 판단-실행-관찰-재추론이 필수 단계로 들어온다.
@tool
def get_weather(city: str) -> str:
"""도시 이름으로 현재 날씨를 조회합니다."""
return weather_api.get(city)
agent = create_react_agent(model, tools=[get_weather])
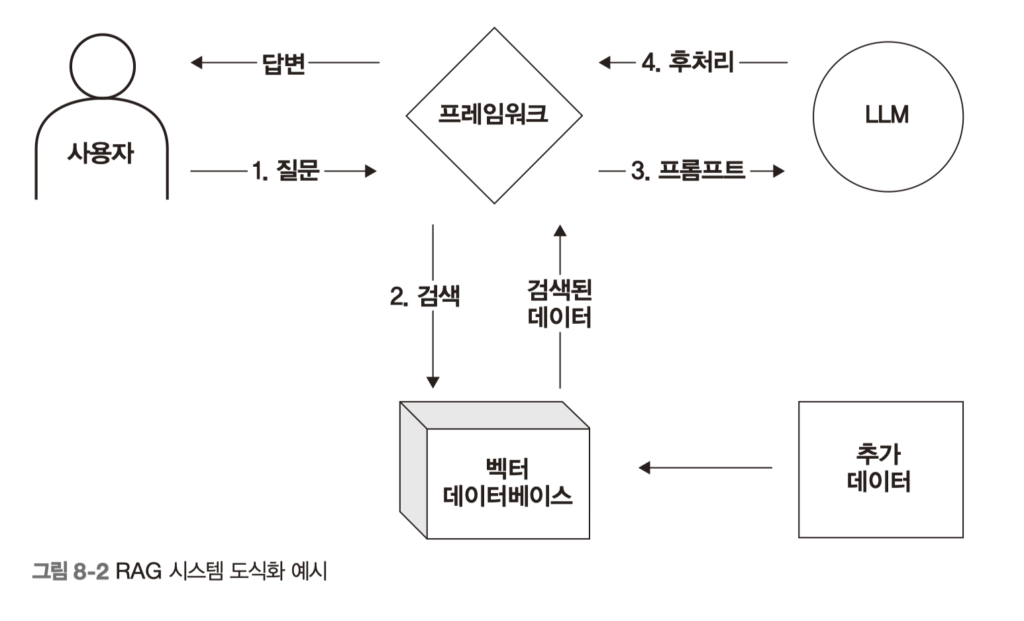
도구를 붙여도 학습 시점 밖 지식은 비어 있어서 결국 RAG로 넘어가고, 검색-증강-생성 흐름 안에서 청킹 균형을 못 맞추면 문맥이 끊기거나 토큰 한계를 넘는다. 메타데이터 필터, Top-k, MMR 조정이 노이즈와 누락을 가르는 기준이었다.
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
)
멀티스텝 질의가 길어지면 선형 체인이 막혀서 상태 지향 그래프로 전환되고, 체크포인터로 도구 선택 정보와 실행 결과, 다음 단계까지 남겨야 장애 원인이 보인다. 긴 대화에서는 요약 미들웨어 튜닝까지 따라온다.
graph = StateGraph(AgentState)
graph.add_node("agent", agent_node)
graph.add_node("tools", tool_node)
graph.add_edge("tools", "agent")
graph.add_conditional_edges("agent", should_continue)
app = graph.compile(checkpointer=MemorySaver())
마지막엔 연동 코드를 프로젝트마다 복붙하는 방식이 유지보수 병목이 되어 MCP 아키텍처로 수렴했고, FastMCP 서버를 독립 자산으로 두니 다른 AI 앱에도 재사용 경로가 열린다. 종합 프로젝트에서 LCEL, Runnable, 메모리, 체크포인트, 에이전트, RAG, LangGraph, MCP가 한 번에 만나는 이유가 여기서 완성된다.
from fastmcp import FastMCP
mcp = FastMCP("my-server")
@mcp.tool()
def get_server_status(server_id: str) -> dict:
"""서버 상태를 조회합니다."""
return openstack.compute.get_server(server_id)
FastMCP 서버를 실제로 세우는 시작점인 mcp = FastMCP("my-server") 선언은 재사용 전략의 출발점이었다. LangGraph 체크포인터와 MCP 서버를 같이 놓고 보니 관측성과 재사용성이 같은 축에서 묶인다. 한쪽은 실행 이력을 남기고, 다른 한쪽은 연동 규약을 고정한다. 이 조합이 갖춰져야 장애 원인을 추적하고 수정 범위를 빠르게 줄일 수 있었다. 결국 마지막 장의 통합 프로젝트는 “많이 붙였다”가 아니라 “어디서 실패해도 복구 경로가 보인다”는 상태를 목표로 한다.
LCEL에서 시작한 작은 체인이 여기서 서비스 파이프라인으로 확장된다. 중간에 배운 병렬 처리, 라우팅, 메모리, 도구, 검색, 상태 관리, 연동 분리를 한 번에 재사용한다. 그래서 이 섹션은 기능 목록보다 빌드업 경로를 따라가며 복기하는 편이 훨씬 유효했다. 실무 기준으로 보면 이 경로를 재현하는 순간부터 데모와 운영의 간격이 급격히 줄어든다. 끝까지 따라가며 구현하면 “왜 이 단계가 필요한가”가 기능보다 먼저 머리에 남는다. 그래서 나중에 스택을 바꿔도 빌드업 순서는 그대로 재사용된다.
에이전트의 완성도는 통합 단계에서 드러난다
후반부 에이전트, LangGraph, MCP, 그리고 종합 프로젝트는 “잘 답하는 봇”에서 “운영 가능한 시스템”으로 넘어가는 단계다. ReAct 패턴을 통해 추론-행동-관찰 루프를 설명하는 방식도 좋았지만, 더 좋았던 건 도구를 함수 계약으로 다루는 태도였다. 툴 설명이 모호하면 잘못된 호출이 늘고, 호출이 늘면 비용과 장애 포인트가 같이 증가한다는 지점은 현업에서 바로 체감되는 내용이다. 도구를 많이 붙이는 것보다, 어떤 질문에서 어떤 도구를 왜 호출해야 하는지 경계를 분명히 하는 편이 훨씬 중요하다.
MCP 파트는 내 경험과 가장 강하게 연결됐다. OpenStack MCP Server를 시작한 배경도 결국 같았다. Horizon 웹 UI, CLI, REST API를 각각 익혀야만 클라우드 리소스를 다룰 수 있는 복잡도를 자연어 인터페이스로 낮추고, knowledge cutoff 한계 때문에 현재 인프라 상태를 모르는 모델에 실시간 도구 연결을 붙여야 했기 때문이다. 그래서 특정 에이전트에 종속되는 방식 대신 MCP의 Tool/Prompt/Resource 계약을 채택했고, 서버 계층이 OpenStack SDK 호출을 맡도록 분리하니 Cursor, Claude, ChatGPT 같은 서로 다른 클라이언트에서도 같은 서버를 재사용하면서 VM 생성·조회·제어, 라우터/보안그룹 관리, Horizon용 MCP Client까지 한 흐름으로 묶였다. 초기에 에이전트 내부에 연동 로직을 직접 넣었을 때는 빠르게 보였지만 API 정책 변화나 권한 모델 이슈가 생기자 유지보수가 급격히 어려워졌고, 반대로 서버 계층을 분리하고 호출 계약을 명확히 하니 테스트 범위와 책임 경계가 깔끔해졌다는 점에서 책 p.274의 “표준화”가 추상 개념이 아니라 운영 설계 원칙으로 읽혔다.
전체적으로 이 책은 입문서와 실무서의 중간 지점을 잘 잡는다. 처음 AI 에이전트를 접하는 사람에게는 빠르게 손을 움직일 수 있는 실습 경로를 주고, 이미 서비스에 적용 중인 개발자에게는 어디를 고쳐야 품질이 안정되는지 점검표를 준다. 단, 아무 배경 없이 바로 읽기에는 초반부터 다루는 범위가 넓어서 난이도가 높게 느껴질 수 있다. 파이썬 기본 문법, API 호출, JSON 데이터 구조 정도는 알고 들어가야 흡수 속도가 확실히 좋다. 그 전제만 갖추면, “요즘 유행하는 키워드를 얕게 훑는 책”이 아니라 설계와 운영까지 생각하게 만드는 책으로 읽힐 것이다.
내 기준에서 추천 대상은 분명하다. 사내 지식검색, 운영 보조, 고객 응대 자동화처럼 “대화형 기능을 실제 서비스로 붙여야 하는” 백엔드/플랫폼 개발자에게 특히 유용하다. 반대로 모델 원리의 수학적 깊이만 집중해서 파고들고 싶은 독자라면 다소 아쉬울 수 있다. 이 책은 모델 내부 이론보다 시스템 통합과 구현 의사결정에 무게를 두기 때문이다. 개인적으로는 최근 해왔던 AI 에이전트 업무를 정리하고, 다음 단계에서 무엇을 개선해야 하는지 우선순위를 다시 잡는 데 큰 도움을 받았다. 읽고 나면 “무엇을 만들까”보다 “어떻게 운영 가능한 형태로 만들까”를 먼저 고민하게 된다.
“한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다.”