

Resilience4j에 NPE 버그픽스 기여한 이야기
Resilience4j Retry에서
throw null이 만들어지는 구조: 결과 기반 재시도와 인터럽트가 만났을 때
먼저 알아야 할 것
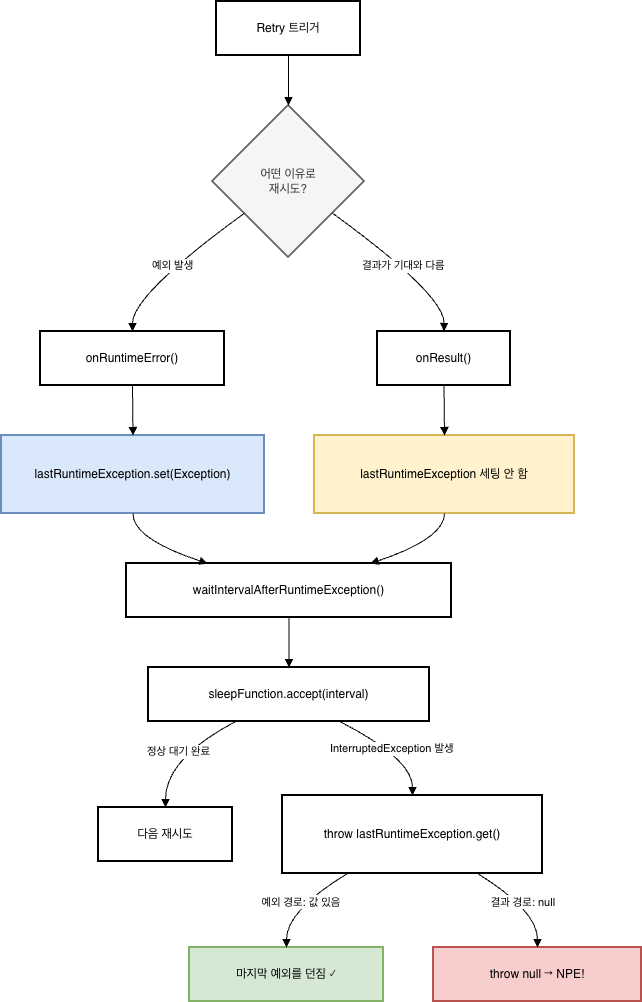
Resilience4j의 Retry는 재시도를 트리거하는 방식이 두 가지다.
첫 번째는 예외 기반 재시도. DB 커넥션이 끊기거나 타임아웃이 발생하면 예외가 던져지고, 라이브러리는 이걸 감지해서 재시도한다. 직관적이고, 대부분의 재시도가 이 경로를 탄다.
두 번째는 결과 기반 재시도 retryOnResult. 예외는 안 났는데 응답 자체가 기대와 다른 경우, 예를 들어 파일 목록을 조회했는데 빈 리스트가 돌아온 경우를 재시도 트리거로 삼는다. 이 경로에서는 에러가 발생한 게 아니니까, 라이브러리 내부에 마지막으로 발생한 예외가 기록되지 않는다. 처음 코드를 읽을 때는 이 차이가 얼마나 중요한지 바로 와닿지는 않았다.
두 경로 모두 다음 시도 전에 일정 시간을 대기하는 구간이 있다. 동기 컨텍스트에서는 Thread.sleep, 혹은 이를 추상화한 sleepFunction을 통해 대기하는데, 이 대기 구간에서 스레드 인터럽트가 발생할 수 있다. Kubernetes pod 스케일링 다운이나 ExecutorService.shutdownNow() 호출, Future.cancel(true) 같은 상황은 운영 환경에서 흔하게 벌어진다.
나중에 돌아보면, 결과 기반 재시도로 대기하는 도중에 인터럽트가 들어오면 어떻게 되는가, 가 문제였다.
두 경로가 내부적으로 어떻게 흘러가는지를 그려보면 이렇다.
이슈를 만나기 까지
사내에서 외부 API 콜 폭주를 제어하기 위해 Resilience4j를 도입하면서 retry 패턴을 적용하고 있었다. 그 과정에서 retryOnResult를 써서 결과 기반 재시도를 구성했는데, 특정 상황에서 예상치 못한 NPE가 터지는 걸 발견했다. 재시도 대기 중에 스레드가 인터럽트되면 정상 종료가 아니라 NullPointerException이 발생하는 현상이었다.
처음에는 내 설정이 잘못된 건가 싶었는데, GitHub에서 검색해보니 똑같은 증상을 겪은 사람이 이미 이슈를 올려놓았다. #2368이었다. 제보 내용도 구체적이었다.
Supplier<List<Path>> filesSupplier = () -> getSomething();
RetryConfig config = RetryConfig.<List<Path>>custom()
.maxAttempts(10)
.waitDuration(Duration.ofMillis(1000))
.retryOnResult(List::isEmpty)
.build();
Retry retry = RetryRegistry.of(config).retry("myRetry");
이 설정으로 결과 기반 재시도를 수행하는 중 스레드가 인터럽트되면, 정상 종료 대신 이런 스택트레이스가 터진다.
java.lang.NullPointerException: Cannot throw exception because the return
value of "java.util.concurrent.atomic.AtomicReference.get()" is null
at io.github.resilience4j.retry.internal.RetryImpl$ContextImpl
.waitIntervalAfterRuntimeException(RetryImpl.java:291)
v2.2.0과 v2.3.0 모두에서 동일하게 재현된다고 했다. 이 정도면 해볼 만하다고 생각했다.
첫 번째 가설
#2368 을 접하고 이슈의 스택트레이스를 읽었을 때, 떠오른 가설은 비교적 단순했다.
retryOnResult로 재시도하는 경우에는 “마지막 예외”가 존재하지 않을 수 있다.- 그런데 구현이 “대기 중 인터럽트 발생 → 마지막 예외를 던진다”는 예외 기반의 전제를 그대로 적용하고 있다면,
- 대기 중 인터럽트 →
lastRuntimeException.get()→null→throw null→ NPE가 되는 것이 아닐까?
그럴듯해 보이긴 했지만, 가설일 뿐이었다. 먼저 재현을 테스트로 고정해서 이게 진짜인지 확인하고, 그 다음에 어떤 예외를 던져야 하는가?를 결정해야 했다.
시행착오
처음에는 내부 구현체인 RetryImpl.Context를 직접 호출하는 방식으로 재현을 시도할 수 있었다. 하지만 곧 의문이 생겼다. ‘이 테스트는 사용자가 실제로 쓰는 API 흐름을 타고 있는가?’
내부 구현을 찌르는 것보다 public API를 통해 재현하는 편이 리뷰어 입장에서 받아들이기 쉽지 않을까 싶었다. 내부 구현은 리팩토링에 취약하고, 이슈 제보자의 사용 패턴과 동일한 컨텍스트임을 보장하기 어렵기 때문이다.
그래서 목표를 재설정했다.
재현 테스트는
RetryConfig → Retry.of(...) → Retry.decorateSupplier(...).get()흐름으로 만든다.
결과적으로 이 선택은 PR 리뷰에서도 별도의 논쟁 없이 수용되었는데, 당시에는 이게 맞는 방향인지 반신반의하면서 진행한 부분이었다.
코드를 읽으면서 보인 것들
빌드 환경을 안정화한 뒤, 코드를 좀 더 꼼꼼히 읽기 시작했다. 읽으면서 몇 가지 눈에 띄는 것들이 있었다.
결과 기반 재시도가 “예외 기반 이름의 메서드”를 쓰고 있다
RetryImpl의 onResult() 메서드를 보면, 결과 기반 재시도에서 대기가 필요할 때 호출하는 메서드가 waitIntervalAfterRuntimeException이다.
@Override
public boolean onResult(T result) {
if (null != resultPredicate && resultPredicate.test(result)) {
totalAttemptsCounter.increment();
int currentNumOfAttempts = numOfAttempts.incrementAndGet();
if (currentNumOfAttempts >= maxAttempts) {
return false;
}
// ...
waitIntervalAfterRuntimeException(currentNumOfAttempts, Either.right(result));
return true;
}
return false;
}
메서드 이름에 RuntimeException 이 들어있지만, 결과 기반 경로에서도 같은 메서드를 쓴다. 그리고 onResult()는 lastRuntimeException.set(...)을 호출하지 않는다. lastRuntimeException에 값을 넣는 곳은 오직 onRuntimeError()뿐이다.
@Override
public void onRuntimeError(RuntimeException runtimeException) {
// ...
lastRuntimeException.set(runtimeException); // 여기서만 설정됨
throwOrSleepAfterRuntimeException();
// ...
}
그러니까 결과 기반 재시도 흐름에서 waitIntervalAfterRuntimeException에 들어갈 때 lastRuntimeException은 항상 null이다.
인터럽트는 에러가 아니라 취소 신호다
Thread.sleep() 같은 블로킹 호출이 인터럽트되면 InterruptedException이 발생한다. 이때 중요한 게 있는데, 블로킹 메서드는 예외를 던지면서 인터럽트 상태를 클리어해버리는 경우가 많다. 그래서 catch 블록에서 Thread.currentThread().interrupt()로 인터럽트 상태를 다시 세팅해줘야 한다. 인터럽트는 단순 실패가 아니라, 상위 레벨로 전파되어야 하는 제어 신호다.
그래서 throw null이 된다
버그가 발생하던 기존 코드는 이렇게 생겼다.
try {
sleepFunction.accept(interval);
} catch (InterruptedException ex) {
Thread.currentThread().interrupt();
throw lastRuntimeException.get(); // ← 여기서 NPE
}
예외 기반 재시도에서 인터럽트가 발생하면 lastRuntimeException에 값이 있으니까 정상 작동한다. 하지만 결과 기반 재시도에서는 예외가 발생한 적이 없으니 lastRuntimeException.get()이 null을 돌려준다. Java에서 throw null은 NullPointerException으로 이어진다.
이것은 ‘특정 조건에서 무한루프에 빠지는 엣지 케이스’ 같은 게 아니었다. 인터럽트를 받았는데 전혀 다른 에러를 내며 폭발하는 현상이었고, 코드를 여기까지 따라오니 가설이 맞다는 확신이 좀 더 생겼다.
그래서 뭘 던져야 하는가
테스트로 재현을 고정하고 코드 경로를 추적하면서, 원인에 대해서는 어느 정도 확신이 생겼다. 하지만 원인을 알았다와 고쳤다는 다른 문제다. 여기서부터는 코드 수정 자체보다 ‘그래서 뭘 던져야 하는가?‘ 라는 스펙 쪽 질문이 남았다.
NPE 대신 무엇을 던져야 하는가?
결과 기반 재시도에서 대기 중 인터럽트가 발생했을 때, 던질 마지막 예외가 없다. 이 빈 자리를 뭘로 채울지 두 가지 후보를 놓고 고민했다.
후보 1: IllegalStateException
구현이 간단하고, 예상하지 못한 상태에 들어왔다는 뉘앙스를 전달할 수 있다. 하지만 이 예외는 보통 프로그래밍 오류, 예를 들어 잘못된 호출 순서나 초기화 누락 같은 상황에 쓴다. 인터럽트는 프로그래밍 오류가 아니라 외부에서 들어온 정당한 제어 신호이므로, 의미가 맞지 않는다.
후보 2: CancellationException
java.util.concurrent.CancellationException은 Future나 ExecutorService 같은 비동기 작업 환경에서 작업이 완료되기 전에 의도적으로 취소되었음 을 알리는 표준 예외다. RuntimeException을 상속한 unchecked 예외이므로 기존 메서드 시그니처를 깨지 않으면서도, 호출자에게 ‘이건 에러가 아니라 취소야’ 라는 맥락을 전달할 수 있다.
판단 기준으로 삼은 것은 두 가지였다.
- 최소 변경으로 버그를 제거할 것. ‘마지막 결과를 저장한다’ 거나 하는 큰 구조 변경까지 가는 건 첫 기여 PR에서 감당하기 어렵다.
- 인터럽트는 취소니까, 그 의미를 코드로 드러낼 것.
인터럽트 = 취소 라는 관점이 더 자연스럽다고 느꼈고, 호출자 입장에서도 CancellationException을 받으면 ‘작업이 취소되었구나’ 라고 바로 판단할 수 있을 것 같았다. Kubernetes pod 스케일링 다운 같은 시나리오에서 모니터링 시스템이 NPE 대신 CancellationException을 보게 된다면, 불필요한 경보가 줄어들고 원인 파악도 쉬워질 것이라 생각했다.
메인테이너가 어떻게 볼지는 PR을 올려봐야 알 수 있는 일이지만, 일단 CancellationException 쪽이 더 설득력이 있다고 판단하고 진행하기로 했다.
최종 수정
수정의 방향은 결국 이렇게 정리되었다.
결과 기반 재시도 대기 중 인터럽트가 발생하면, NPE가 아니라 ‘취소’로 종료되어야 한다. 인터럽트 플래그는 유지되어야 한다.
최종 커밋(09e4502)에서 RetryImpl.java의 waitIntervalAfterRuntimeException 메서드를 다음과 같이 수정했다.
try {
sleepFunction.accept(interval);
} catch (InterruptedException ex) {
Thread.currentThread().interrupt();
RuntimeException last = lastRuntimeException.get();
if (last != null) {
throw last;
}
CancellationException cancellationException = new CancellationException( // ← 추가
"Thread was interrupted during retry wait interval");
cancellationException.initCause(ex);
throw cancellationException;
}
catch (Throwable ex) {
RuntimeException last = lastRuntimeException.get();
if (last != null) {
throw last;
}
throw new IllegalStateException("Unexpected exception during retry wait interval", ex);
}
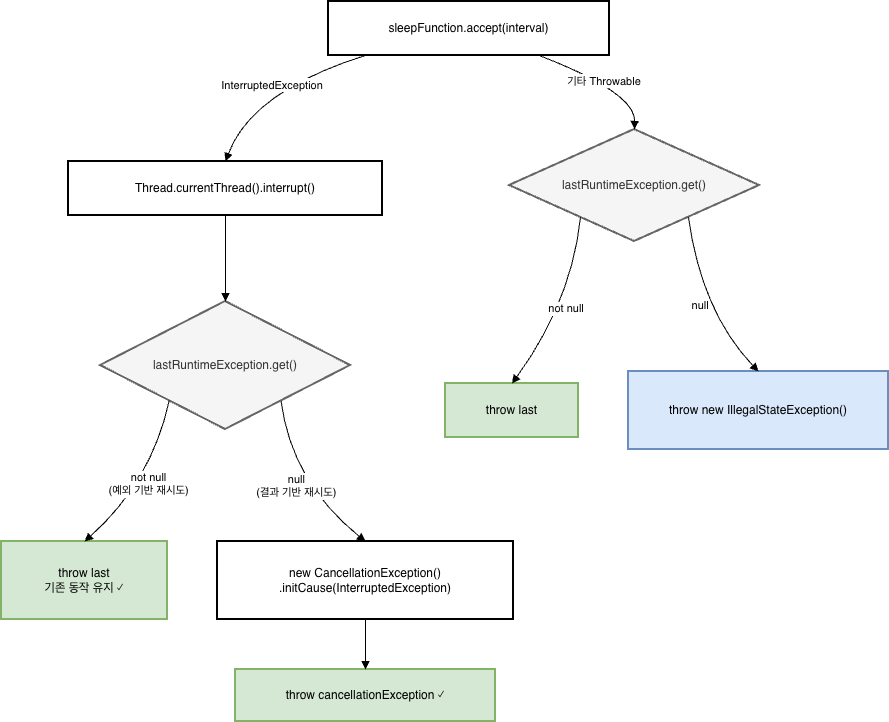
수정 후의 흐름을 그려보면 이렇다.
바뀐 건 크게 세 가지다.
InterruptedException을 잡았을 때, lastRuntimeException.get()이 null인지 먼저 본다. 예외 기반 재시도였다면 기존 동작 그대로 마지막 예외를 던지고, 결과 기반 재시도여서 null이면 CancellationException을 만들어 던진다. 원본 InterruptedException은 initCause()로 연결해서 디버깅 단서를 남긴다.
Throwable catch 블록도 같은 null 가능성이 있어서, lastRuntimeException이 없으면 IllegalStateException으로 감싸 던지도록 했다. 인터럽트와 달리 이쪽은 “예기치 못한 예외”니까 IllegalStateException이 맞다.
Thread.currentThread().interrupt()는 기존에도 호출되고 있었고, 그대로 유지했다.
테스트
재현 테스트에서 가장 신경 쓴 부분은 인터럽트를 결정적으로 만드는 것이었다. 실제 Thread.interrupt()를 쓰면 타이밍에 의존하는 불안정한 테스트가 되기 쉽다.
대신 RetryImpl.sleepFunction을 직접 교체해서 InterruptedException을 무조건 던지도록 강제하는 방식을 택했다.
@Test
public void shouldThrowCancellationExceptionWhenInterruptedDuringRetryOnResult() {
CheckedConsumer<Long> previousSleepFunction = RetryImpl.sleepFunction;
try {
RetryImpl.sleepFunction = sleep -> { // mocking
throw new InterruptedException("Interrupted!");
};
RetryConfig retryConfig = RetryConfig.<String>custom()
.retryOnResult(result -> true)
.maxAttempts(3)
.build();
Retry retry = Retry.of("id", retryConfig);
Supplier<String> decorated = Retry.decorateSupplier(retry, () -> "any");
assertThatThrownBy(decorated::get)
.isInstanceOf(CancellationException.class)
.hasMessage("Thread was interrupted during retry wait interval");
assertThat(Thread.currentThread().isInterrupted()).isTrue();
} finally {
RetryImpl.sleepFunction = previousSleepFunction;
Thread.interrupted();
}
}
RetryConfig → Retry.of → Retry.decorateSupplier(...).get()으로 사용자가 실제로 쓰는 public API 경로를 그대로 탄다. 검증하는 건 두 가지다. 결과 기반 재시도 상황에서 인터럽트가 들어왔을 때 CancellationException이 발생하는지, 그리고 스레드의 interrupt flag가 유지되는지.
finally 블록에서 sleepFunction을 원래 값으로 복원하고 Thread.interrupted()로 플래그를 클리어하는 것은 다른 테스트에 영향을 주지 않기 위한 teardown이다.
PR 결과
변경 규모는 RetryImpl.java , SupplierRetryTest.java . 메인테이너와 리뷰어의 승인을 받아 master에 머지되었고, 이 버전은 v2.4.0에 태그 되었다.
돌아보며
재현을 테스트로 고정할 수 있느냐가 거의 전부였다
이번에 느낀 건, 버그를 테스트로 결정적으로 재현할 수 있느냐가 오픈소스 기여에서 거의 전부라는 점이었다. 타이밍이나 환경에 의존하는 버그는 재현 자체가 불안정하고, PR을 올려도 ‘이거 정말 고쳐진 거 맞아?’ 에 대한 근거가 약해진다. 이번 이슈는 sleepFunction을 교체하는 것만으로 결정적 재현이 가능했고, 그 덕에 수정에 대한 확신도 생기고 리뷰도 수월하게 넘어갈 수 있었다.
‘마지막 예외가 있다’ 는 전제를 의심하지 못했던 이유
이번 버그의 구조를 한마디로 줄이면, waitIntervalAfterRuntimeException이라는 메서드를 예외 기반 경로와 결과 기반 경로가 같이 쓰고 있었는데, 결과 기반 경로에서는 “마지막 예외”가 채워지지 않는다는 것이다. 예외가 발생해서 재시도하는 게 아니라 결과값이 마음에 안 들어서 재시도하는 거니까, 당연히 예외가 없다.
그런데 코드만 봐서는 이게 잘 안 보인다. 메서드 이름에 RuntimeException 이 들어있으니 ‘이 메서드에 들어올 때는 당연히 예외가 있겠지’ 라고 자연스럽게 생각하게 된다. 실제로 onResult()에서도 이 메서드를 호출하고 있다는 걸 확인하고 나서야 아, 이 메서드가 예외 없이도 불릴 수 있구나 를 알게 되었다.
인터럽트는 에러가 아니라 제어 신호다
인터럽트를 catch할 때 흔히 빠지는 실수는 이것도 에러의 일종으로 취급하는 것이다. 하지만 인터럽트는 ‘이 작업을 중단해달라’ 는 외부의 정당한 요청이다. 그래서..
- 인터럽트 상태를 삼키지 말 것 (
Thread.currentThread().interrupt()로 복원) - 상위 레벨이 취소를 감지할 수 있는 예외를 던질 것 (
CancellationException) - 원본
InterruptedException을 cause chain에 보존할 것
클라우드 환경에서 SIGTERM이나 스레드 인터럽트는 일상이다. NPE가 터지면 모니터링 경보가 울리고 진짜 원인을 파악하기 어려워진다. CancellationException으로 표현되어 있으면, 운영 팀이 ‘이건 의도된 중단이지 시스템 오류가 아니다’ 라고 판단하기 훨씬 수월해질 것이다.