

진흙 덩어리에서 마이크로서비스까지, 70개의 패턴이 그리는 지도

한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다.
- 원제 : Cloud Application Architecture Patterns
- 저자 : Kyle Brown, Bobby Woolf, Joseph Yoder
- 출간 : O’Reilly Media, 2025 / 한빛미디어, 2026
추천사에 이런 문장이 있었다. “근본적으로 옮기기 쉬운 소프트웨어들은 이미 클라우드로 전환되었다. 따기 쉬운 열매는 이미 다 땄다.” 이 문장이 책 전체가 서 있는 자리를 압축한다는 생각이 들었다. 이미 클라우드로 옮길 만한 것은 옮겨졌고, 이제 남은 건 옮기기 어려운 것들을 어떻게 옮기느냐의 문제라는 입장이다.
아키텍처는 어떻게 개발하고 실행할 것인가의 문제
저자는 시작부터 애플리케이션 아키텍처가 무엇인지 분명히 한다. 애플리케이션 아키텍처는 애플리케이션의 기능을 정의하는 것이 아니라, 애플리케이션의 기능을 어떻게 개발하고 실행할 것인가를 정의하는 것이라고 말한다. 그래서 아키텍처를 변경하면 기능을 개발하고 실행하는 방법이 바뀐다. 랄프 존슨의 정의도 같이 인용된다. 아키텍처란 “한번 결정하면 바꾸기 어려운 부분들” 또는 “프로젝트 초기에 제대로 결정해야 하는 사항들”이다.
여기서부터 트레이드오프 이야기가 따라온다. 책은 아키텍처 결정 시 고려해야 할 항목을 나열한다. 성능, 가용성, 보안, 유지 보수의 용이성, 수정의 용이성, 출시까지 소요되는 기간, 개발자의 스킬 셋. 이걸 하나씩 짚어보면서 트레이드오프 사이의 균형을 맞추는 것이 아키텍처 결정의 핵심이라는 입장을 깐다.
그리고 책은 모든 아키텍처를 세 가지 핵심 패턴으로 압축한다. 커다란 진흙 덩어리, 모듈러 모놀리식, 분산 아키텍처. 이 세 가지가 책 전체의 좌표축이다.
진흙 덩어리에서 시작해도 괜찮다
가장 카운터인투이티브한 메시지가 진흙 덩어리 챕터에 있다. 저자는 진흙 덩어리를 “아키텍처가 없는 아키텍처”라고 부른다. 모든 구성 요소가 서로 얽혀 있고 순환 참조가 발생하며, 중요한 공유 데이터는 전부 전역 변수로 사용한다. 변수나 함수 이름은 극단적으로 간단하거나 필요한 정보를 제공하지 않거나 심지어 다른 뜻으로 해석될 여지가 있는 잘못된 이름을 사용한다. 처음에 잘 설계된 구조가 시간이 지나면서 뒤섞인 결과일 수도 있고, 즉흥적으로 시도하는 다양한 코드들이 쌓여 진화한 결과일 수도 있다.
이 정의만 보면 진흙 덩어리는 안티 패턴처럼 들린다. 그런데 책은 다른 결론으로 간다. “장기간 유지 보수해야 할 애플리케이션에 커다란 진흙 덩어리 아키텍처를 적용하는 것은 재앙이겠지만 단기간 개발해야 할 애플리케이션에는 커다란 진흙 덩어리가 최적의 아키텍처다.” 데모, 프로토타입, MVP 단계에서는 캡슐화나 재사용성을 따지느라 시간을 허비하기보다 그냥 코드를 짜서 새 기능을 만들고 테스트하는 편이 빠르다는 것이다.
페이팔 사례가 이 메시지를 떠받친다. 페이팔은 1999년에 CGI 한 덩어리로 시작했고, 2007년에는 70개가 넘는 모놀리식이 연결된 형태였다. 그 시점에 도메인 로직을 담당하던 C++ 클래스 하나가 5,000개가 넘는 메서드와 50만 줄짜리 코드를 갖고 있었다. 페이팔 팀은 거기서부터 클래스를 쪼개기 시작했고, 결국 2,500개 이상의 마이크로서비스가 750개 이상의 외부 API를 제공하는 시스템으로 갔다. 진흙 덩어리에서 출발했기 때문에 망한 게 아니라 거기서 출발해서 진화했기 때문에 살아남은 흐름이다.
다만 책은 진흙 덩어리에서 멈추지 말라고 경고한다. 모놀리식의 진짜 문제는 시간이 지나면서 드러난다. 복잡하게 뒤엉킨 코드와 순환 참조 때문에 코드 하나를 수정하면 다른 부분이 망가지고, 다른 개발자가 수정한 부분 때문에 빌드가 실패할 수 있다. 찾기 어렵거나 숨겨진 의존성 때문에 코드 리뷰나 보안 취약점 스캔이 어려워진다. 이 지점에서 모듈러 모놀리식이 등장한다. 응집도가 높고 결합도가 낮은 모듈들로 구조화하고, 모듈 간 의존성을 최소화해 순환 참조를 차단하는 형태다. 단일 프로세스이므로 직렬화 비용이 없고, 같은 프로그래밍 언어로 같은 메서드 호출 방식을 공유하며, 모니터링과 재시작이 용이하다는 장점이 따라온다.
클라우드 네이티브 아키텍처라는 분리
책이 클라우드 네이티브를 정의하는 방식이 흥미로웠다. IBM의 정의가 먼저 인용된다. “클라우드 네이티브는 애플리케이션을 어디서 실행하는가보다 어떻게 빌드하고 배포하는가에 더 중점을 둔다.” 마이크로소프트의 정의도 함께 가져온다. “클라우드 네이티브 아키텍처와 관련 기술은 클라우드에서 워크로드를 설계하고 구축하여 운영하기 위한 접근 방식이며 클라우드 컴퓨팅의 강점을 최대한 활용하는 것을 의미한다.” 두 정의를 종합해 책은 자기만의 정의를 만든다. “클라우드 네이티브는 클라우드 컴퓨팅의 강점을 최대로 활용함과 동시에 클라우드 컴퓨팅의 한계를 피하거나 보완함으로써 클라우드에서 잘 동작할 수 있는 애플리케이션을 설계하는 접근 방식이다.”
이 정의는 두 가지를 동시에 요구한다. 강점의 활용과 한계의 보완. 강점은 탄력적 확장, 셀프 프로비저닝, 멀티테넌시 같은 것이고, 한계는 결과적 일관성, 네트워크 지연, 컴포넌트 단위 장애 같은 것이다. 이 둘을 같이 다뤄야 클라우드 네이티브라는 입장이다.
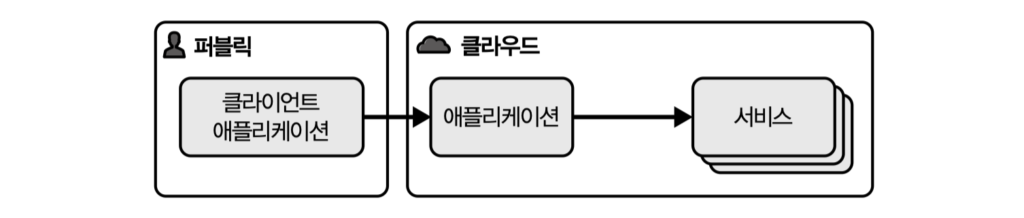
클라우드 네이티브 아키텍처의 구조는 단순하다. 애플리케이션과 서비스 두 부분으로 나뉜다. 애플리케이션은 개발 팀이 프로그래밍 언어로 직접 만드는 도메인 로직이고, 서비스는 클라우드 플랫폼이나 서드파티가 제공하는 백엔드 서비스다. 데이터베이스, 메시지 큐, 인증 같은 미들웨어 기능을 모두 외부 서비스 카탈로그에 위임하라는 입장이다.
이 분리가 강조하는 핵심은 이동성이다. 전통적인 IT 애플리케이션은 보통 하나의 컴퓨터에 설치하여 수명이 다할 때까지 그 컴퓨터에서만 실행되어 왔다. 그래서 특정 하드웨어나 운영 체제에 맞춰 설계되는 경우가 많고, 다른 컴퓨터로 재배포하려면 동일한 사양이 필요했다. 클라우드 환경에서는 부하 분산이나 유지 보수 등을 위해 애플리케이션을 이 컴퓨터에서 저 컴퓨터로 옮겨가며 실행해야 한다. 그래서 애플리케이션은 반드시 쉽게 이동 가능한 형태로 패키징해야 한다. 이 분리를 받아들이면 12팩터 앱이 왜 필요한지, 외부 설정과 스테이트리스가 왜 패턴이 되는지가 자연스럽게 이어진다.
마이크로서비스가 마이크로서비스가 되는 조건
마이크로서비스의 정의도 명료하다. “마이크로서비스 아키텍처는 분산 아키텍처와 클라우드 네이티브 아키텍처의 결합으로 실현한다.” 분산만 있으면 SOA에 가깝고, 클라우드 네이티브만 있으면 클라우드 위에 올린 모놀리식일 뿐이다. 둘 다 갖춰야 마이크로서비스다.
마이크로서비스 유형은 4가지로 나뉜다. 도메인 마이크로서비스, 어댑터 마이크로서비스, 디스패처, 서비스 오케스트레이터. 도메인과 어댑터는 익숙한 분류지만 디스패처와 서비스 오케스트레이터를 패턴화한 자료는 흔치 않다. 디스패처는 BFF, API 게이트웨이, 애그리게이터로 불리는 그것이고 클라이언트 유형마다 따로 두는 패턴이 자세히 다뤄진다. 서비스 오케스트레이터는 콘서트 표 구매처럼 좌석 예약, 비용 지불, 입장권 배송이 한 트랜잭션으로 묶이는 작업을 처리한다.
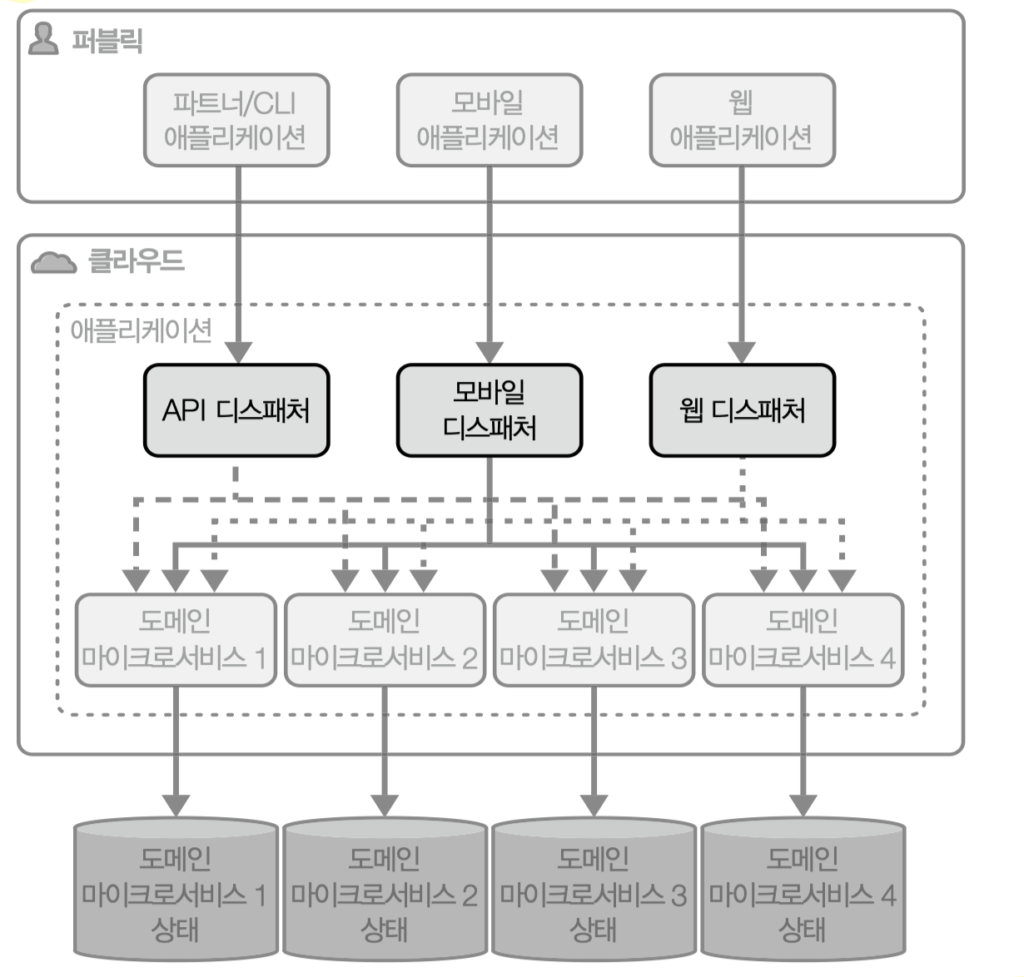
마이크로서비스 설계 원칙으로 책은 IDEALS를 제시한다. SOLID의 마이크로서비스판이라고 부른다. 여섯 글자가 각각 다음을 가리킨다.
인터페이스 분리는 모바일 앱, 웹, CLI 같은 서로 다른 클라이언트 유형마다 자신에게 적합한 API로 호출할 수 있도록 만드는 원칙이다. SOLID의 ISP를 서비스 인터페이스 수준으로 확장한 것에 해당한다. BFF가 대표적인 구현 패턴이다.
배포 가능성은 좋은 설계와 구현만으로 마이크로서비스의 성공을 보장할 수 없다는 인식에서 출발한다. 마이크로서비스 시대에는 배포 단위 수가 크게 증가하므로 컨테이너화, 서버리스, 모니터링과 함께 블루-그린, 카나리, 롤링 같은 배포 전략이 동시에 따라와야 한다.
이벤트 주도는 가능한 한 마이크로서비스를 동기식 요청-응답이 아니라 비동기 메시지나 이벤트로 활성화하라는 권장이다. 게시자와 구독자 모델 위에서 서비스가 직접 호출하지 않고 이벤트 버스로 통신하는 형태다.
일관성보다 가용성은 CAP 정리에서 가용성을 우선하겠다는 선언이다. 일관성이 일시적으로 깨지더라도 사용자 경험을 위해 가용성을 택한다.
느슨한 결합은 의존성이 많은 마이크로서비스는 사실상 분산형 모놀리식이라는 경고다. 책은 이런 시스템을 매크로서비스 또는 마이크로덩어리서비스라고 부른다. 결합 문제를 그대로 안고 분산까지 더해진 셈이라 디버깅이나 분산 트랜잭션이 매우 까다로워진다.
단일 책임은 적정 크기의 마이크로서비스를 모델링하는 원칙이다. 책은 여기서 단호하게 말한다. “마이크로서비스를 지나치게 작게 만드는 것은 마이크로서비스 아키텍처를 만들 때 가장 흔히 저지르는 실수다.” 하한은 최소 1개 애그리거트, 상한은 바운디드 콘텍스트. 이 두 줄로 적절한 크기에 대한 토론이 정리된다.
한 번에 다 갈아엎지 않는 법
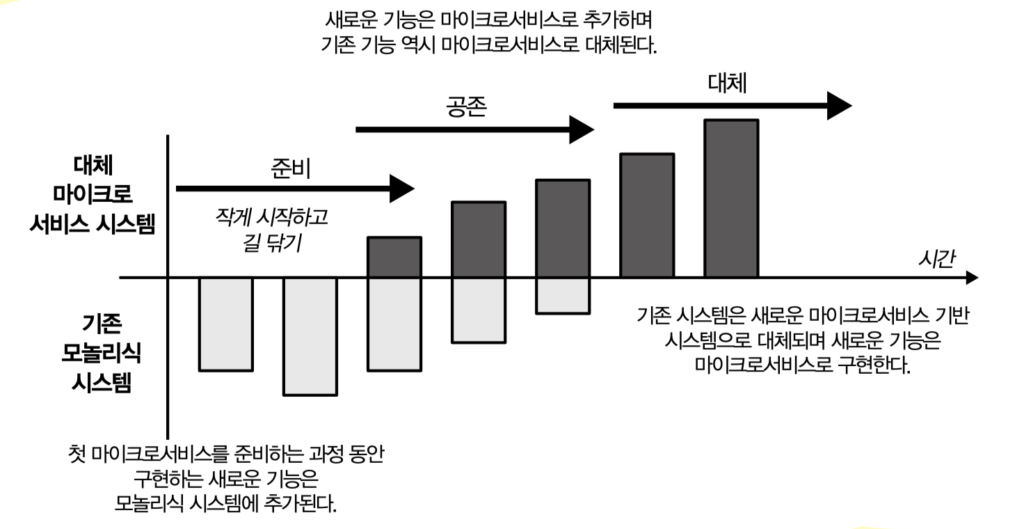
마지막은 모놀리식 점진적 대체에 관한 이야기다. 건드릴 수 없는 모놀리식이 한 덩어리로 서 있고, 위에서는 마이크로서비스로 가자고 하는 흔한 상황. 이걸 어떻게 풀어가는가에 대한 안내서다.
저자는 모놀리식 대체를 두 가지 상호 보완적인 활동으로 정의한다. 기능과 컴포넌트를 버리는 것과 이전하는 것. 모든 코드를 다 옮기겠다는 욕심부터 내려놓으라는 뜻이다. 애플리케이션의 사용 패턴이 빠르게 바뀐 영역은 모놀리식 쪽 기능이 시간이 지나면서 자연스럽게 쓸모없어지는 경우가 많다. 그런 기능은 굳이 옮기지 않고 그냥 버리는 것만으로도 대체가 진행된다. 이전과 폐기를 동시에 다루는 관점이 책의 출발점이다.
전략의 순서가 패턴 카탈로그로 정돈되어 있다는 점이 따라가기 좋았다. 길 닦기, 작게 시작하기, 모놀리식 감싸기, 가느다란 실금 찾기, 컴포넌트 추출, 리팩터링 후 추출, 플레이백 테스트.
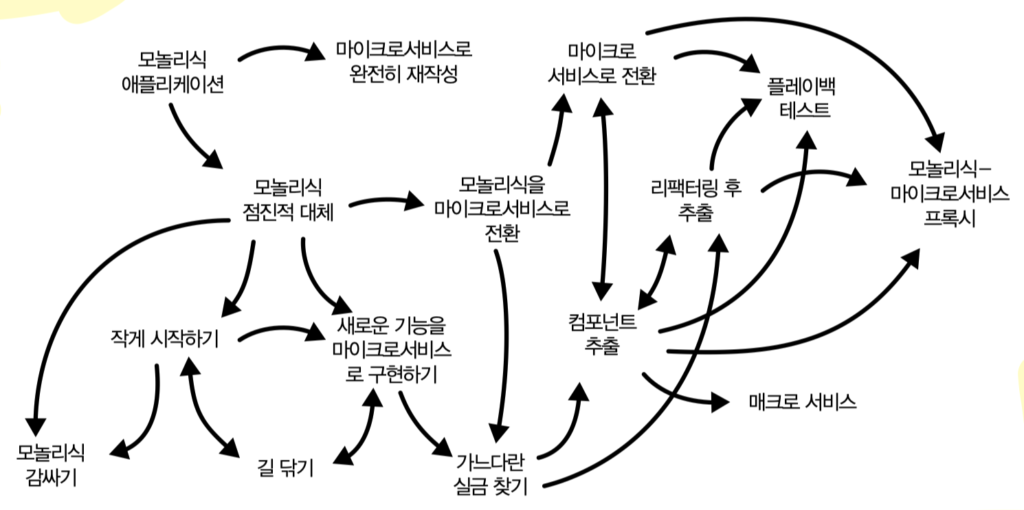
길 닦기는 인프라 준비 단계다. 컨테이너화, 컨테이너 오케스트레이션, 로그 통합, 모니터링, 분산 추적, CI/CD, 외부 설정, 코드형 인프라. 이걸 해놓지 않으면 마이크로서비스를 첫 번째로 뽑아내는 순간부터 바퀴 없이 마차를 끄는 꼴이 된다는 메시지가 분명하게 전달된다.
작게 시작하기는 첫 마이크로서비스를 어디서 만드냐에 대한 답이다. 책은 처음부터 모놀리식을 깎아내려고 하지 말고, 새로 들어오는 기능을 마이크로서비스로 구현하는 것에서 시작하라고 권한다. 마이크로서비스 원칙과 모범 사례를 팀이 학습하는 데 적합하고, 동시에 모놀리식이 더 비대해지지 않도록 막아주는 효과도 있다. 학습과 동결을 동시에 노리는 자리다.
모놀리식 감싸기는 흔히 스트랭글러 파사드라고 부르는 패턴이다. 처음에는 파사드가 모놀리식의 트래픽을 그대로 통과시키기만 한다. 그러다가 일부 기능을 마이크로서비스로 옮기면 파사드가 프로토콜과 형식을 변환해준다. 양방향 통신도 가능하다. 클라이언트는 변경 없이 새 시스템으로 점진 이동하는 구조다.
가느다란 실금 찾기는 모놀리식 안에서 분리할 수 있는 경계 지점을 찾는 단계다. 책이 솔직한 점은, 비즈니스 기능이 코드에 잘 정의되지 않은 경우가 흔하다는 걸 인정한다는 것이다. 그럴 때는 데이터에서 시작해 코드로 거슬러 올라가라는 조언을 한다. 저장 프로시저부터 시작해서 그걸 호출하는 코드를 따라가는 식이다. DB에 비즈니스 로직이 박혀 있는 레거시 시스템에서는 이게 현실적인 출발점이 된다. 복잡하게 얽혀 분리 지점이 잘 보이지 않는 영역에서는 비즈니스 역량을 중심으로 묶으라는 조언이 따라온다. 함께 묶이는 상위 수준의 관련 기능 그룹을 먼저 찾고, 그 안에서 반복되는 작은 사용 사례를 찾고, 마지막으로 마이크로서비스로 구축할 코드 수준의 컴포넌트를 찾는 순서다. 위에서 아래로 점점 좁혀가는 동선이다.
컴포넌트 추출과 리팩터링 후 추출은 실제로 코드를 떼어내는 단계다. 책은 한 번에 작은 마이크로서비스로 곱게 분리하려고 하지 말라고 한다. 큰 기능 조각을 일단 매크로 서비스로 한 덩어리 추출한 뒤, 거기서부터 더 작은 마이크로서비스로 리팩터링하는 재귀적인 프로세스를 권한다. 도메인 개념을 중심으로 모놀리식을 분할 정복으로 분해해 나가는 형태다. 시작 단계에서부터 완성형 마이크로서비스를 만들 필요가 없다는 점이 마음을 좀 가볍게 해주는 부분이었다.
플레이백 테스트는 의외의 발견이었다. 새 마이크로서비스 시스템이 기존 모놀리식과 동일하게 동작하는지 확인하는 방법인데, 원 시스템에서 입력과 동작을 캡처하고 새 시스템에서 같은 입력을 재생해 결과를 비교한다. 단순한 듯하지만 책의 한 문장이 핵심을 짚는다. “기존 시스템의 미묘한 버그조차 워크플로우와 UI에 고착되어 사실상 숨겨지거나 문서화되지 않은 기능이 되었을 수도 있다.” 리팩터링이라는 단어를 평소에 너무 가볍게 썼다는 반성이 따라왔다.
패턴 카탈로그로 그려지는 이행의 동선
책의 흐름을 한 호흡으로 정리하면 이렇다. 출발은 애플리케이션 아키텍처의 세 가지 좌표축인 진흙 덩어리, 모듈러 모놀리식, 분산 아키텍처다. 거기서 클라우드의 강점을 활용하기 위해 클라우드 네이티브 아키텍처가 등장한다. 분산 아키텍처와 클라우드 네이티브가 결합한 자리에 마이크로서비스가 자리 잡고, 마이크로서비스 설계는 IDEALS 원칙과 도메인 중심 모델링으로 다듬어진다. 그리고 마지막으로 이미 존재하는 모놀리식을 어떻게 이 새 좌표계로 옮길지를 점진적 대체 패턴으로 이어간다. 70개의 패턴이 한 줄로 묶이지는 않지만 각 패턴이 어디에 자리 잡는지 동선이 그려져 있다.
코드 예시는 적은 편이다. 자바 인터페이스, JAX-RS, Go 인터페이스, OpenAPI 정의 정도가 등장한다. 책의 부제가 70가지 패턴이듯, 이 책은 패턴을 다루지 구현을 다루지 않는다. 구현 디테일은 같은 시리즈의 다른 책이나 클라우드 플랫폼별 가이드에서 채우는 식으로 보면 자연스럽다.
읽기 전에 알고 있으면 도움이 되는 지식은 REST와 RPC 통신, 컨테이너와 쿠버네티스 개념, CAP 정리와 결과적 일관성 같은 분산 시스템 기본, 그리고 DDD의 기본 용어 정도다. DDD를 모르고 봐도 마이크로서비스 설계 챕터가 입문 역할을 해주는 편이지만, 막히면 에릭 에반스나 반 버논의 책을 먼저 보고 돌아오는 편이 낫다.
작년에 ‘소프트웨어 아키텍처 The Hard Parts’를 읽으면서 분산 아키텍처의 트레이드오프 분석에 익숙해진 후라 이 책은 그 다음 단계로 잘 어울렸다. ‘소프트웨어 아키텍처 The Hard Parts’가 ‘왜 이 아키텍처를 골랐나’에 대한 분석 도구를 줬다면, 이 책은 ‘그래서 어떤 패턴들로 어떻게 만드는가’를 카탈로그로 보여준다. 두 책을 같이 책장에 두면 좋겠다는 생각이 들었다.
처음에는 챕터 순서대로 따라 읽다가, 어느 순간부터는 작업이 막힐 때마다 해당 챕터를 펼쳐서 패턴 이름과 그림만 보고 돌아가는 방식이 자리 잡혔다. 패턴 사전이라고 생각하면 이 책을 가장 잘 쓰는 방법은 그 방식이라는 생각이 든다.
한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다.