인스턴스 백업/복구 서브시스템
기간: 2025.06 ~ 2025.08
역할: 시스템 설계 및 개발
기술스택: Spring Scheduling, Cinder API, Queue/Worker Architecture
프로젝트 개요
사용자 정의 스케줄 기반 자동 백업과 증분/전체 백업 체인 관리를 통해 완전한 복구 재현성을 확보하는 엔터프라이즈급 백업 시스템 개발
핵심 성과: 장기 보관 시 스토리지 효율성 극대화 | 증분→Full 자동 폴백 | 완전한 인스턴스 복구
시스템 아키텍처
전체 데이터 모델 (ERD)
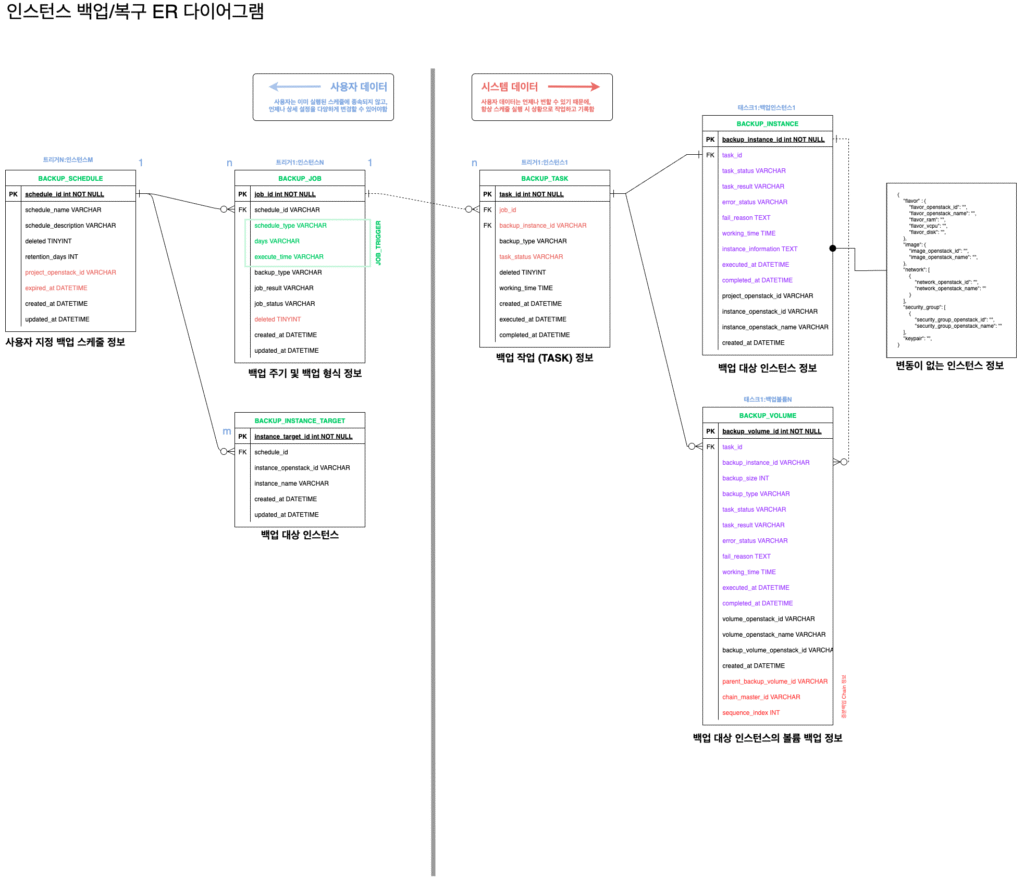
핵심 엔티티 관계:
- JOB ←1:N→ BACKUP_SCHEDULE: 하나의 Job에 여러 스케줄 정의 가능
- BACKUP_SCHEDULE ←1:N→ BACKUP_INSTANCE_TARGET: 스케줄별 대상 인스턴스들
- BACKUP_TASK ←1:N→ BACKUP_INSTANCE: Task 단위로 인스턴스 백업 관리
- BACKUP_INSTANCE ←1:N→ BACKUP_VOLUME: 인스턴스별 볼륨들의 백업 정보
백업 워크플로우
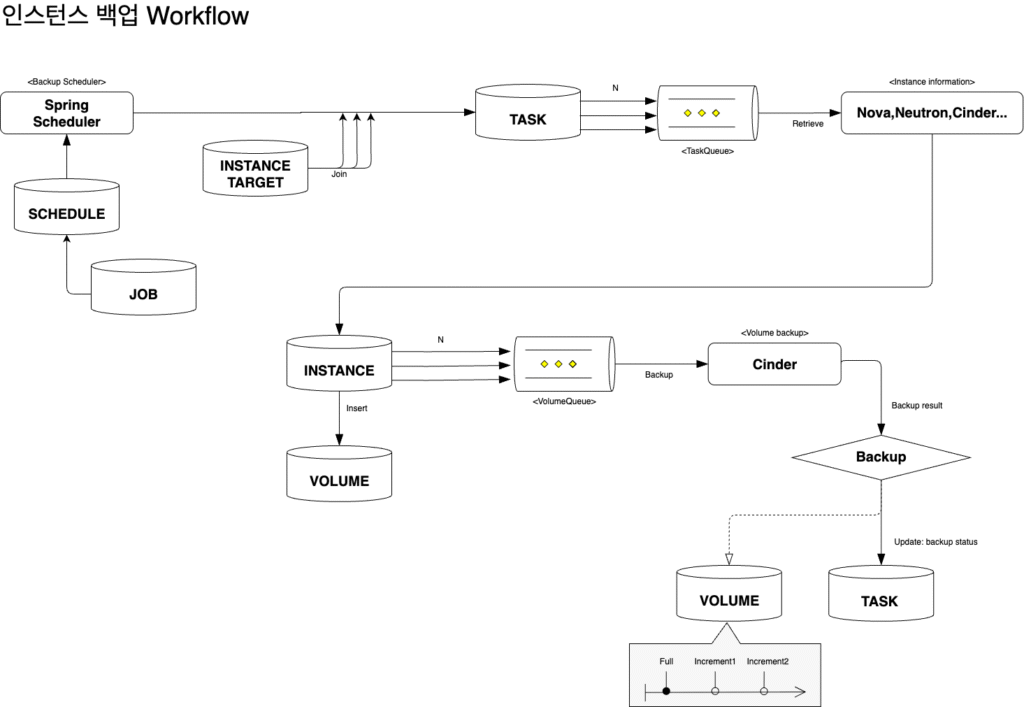
처리 파이프라인:
- Spring Scheduler → 사용자 정의 스케줄 검사
- SCHEDULE + INSTANCE_TARGET → 백업 대상 결정
- TASK Queue → 인스턴스 단위 작업 생성
- Volume Queue → 볼륨별 순차 백업
- Cinder API → 실제 백업 수행 및 상태 모니터링
복구 워크플로우
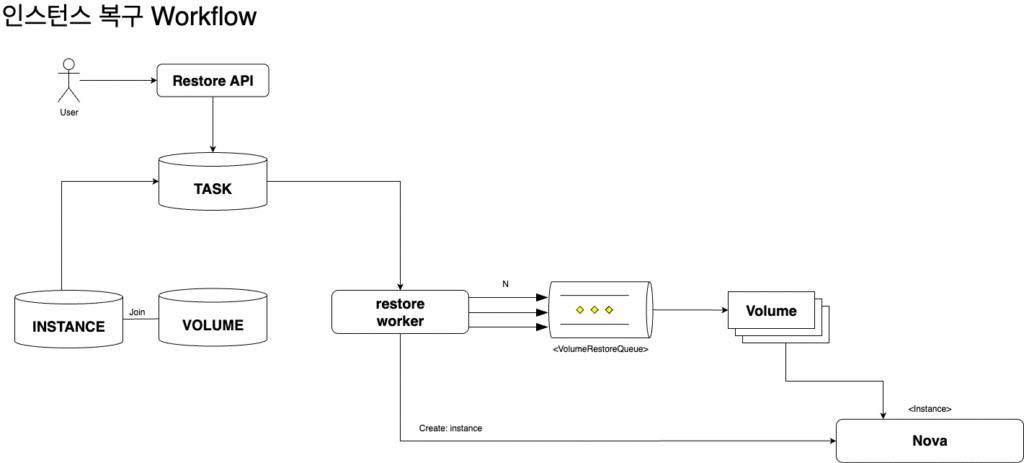
복구 파이프라인:
- TASK + INSTANCE + VOLUME → 복구 대상 정보 조회
- Volume Restore Queue → 볼륨별 복구 작업
- Cinder Volume Restore → 백업에서 볼륨 복구
- Nova Instance Create → 복구된 볼륨으로 인스턴스 재생성
사용자 커스텀 스케줄링 시스템
1) 유연한 스케줄 정의
사용자가 다양한 패턴으로 백업 스케줄 정의 가능:
// 백업 스케줄 엔티티 설계 (ERD 기반)
@Entity
public class JobBackupSchedule {
private String scheduleName;
private String projectId;
private BackupType backupType; // FULL, INCREMENTAL
// 다양한 스케줄 패턴 지원
private ScheduleType scheduleType; // DAILY, WEEKLY, MONTHLY, CUSTOM
private String cronExpression; // 커스텀 cron 패턴
// 요일별 설정 (Weekly용)
private Set<DayOfWeek> weeklyDays; // [MON, WED, FRI]
// 월별 설정 (Monthly용)
private Integer monthlyDay; // 매월 15일
// 시간 설정
private LocalTime executionTime; // 02:30:00
// 보관 정책
private Integer retentionDays; // 30일 보관
private Boolean isEnabled; // 스케줄 활성화
}
2) 스케줄 패턴별 Cron 표현식 자동 생성
public class CronExpressionUtil {
public static String toCronExpression(JobBackupScheduleResponse schedule) {
ScheduleType type = schedule.getScheduleType();
LocalTime time = schedule.getExecutionTime();
int hour = time.getHour();
int minute = time.getMinute();
switch (type) {
case DAILY:
// 매일 지정 시간 (예: 매일 새벽 2:30)
return String.format("0 %d %d * * *", minute, hour);
case WEEKLY:
// 지정 요일들에 실행 (예: 월,수,금 02:30)
String dayOfWeekStr = schedule.getWeeklyDays().stream()
.map(day -> String.valueOf(day.getValue()))
.collect(Collectors.joining(","));
return String.format("0 %d %d * * %s", minute, hour, dayOfWeekStr);
case MONTHLY:
// 매월 지정 날짜 (예: 매월 15일 02:30)
return String.format("0 %d %d %d * *", minute, hour, schedule.getMonthlyDay());
case CUSTOM:
// 사용자 직접 입력한 cron 표현식
return schedule.getCronExpression();
}
}
}
3) 스케줄 누락 보정 로직
운영 환경에서 스케줄 드리프트나 시스템 지연을 고려한 보정 메커니즘:
@Scheduled(cron = "0 */10 * * * *") // 매 10분마다 실행
public void executeBackupScheduler() {
log.info("Executing Backup Scheduler");
List<JobBackupScheduleResponse> schedules = jobManager.retrieveSchedule();
LocalDateTime now = LocalDateTime.now();
for (JobBackupScheduleResponse schedule : schedules) {
if (!schedule.getIsEnabled()) continue;
String cronExpression = CronExpressionUtil.toCronExpression(schedule);
CronExpression cron = CronExpression.parse(cronExpression);
// 현재 시점 매칭 검사
boolean isCurrentMatched = isMatched(cron, now);
// 최근 1분 윈도우 내 누락된 실행 검사 (지연 보정)
boolean isMissedInRecentWindow = false;
for (int i = 1; i <= 6; i++) { // 최근 60초간 10초 간격으로 체크
LocalDateTime pastTime = now.minusSeconds(i * 10);
if (isMatched(cron, pastTime) && !wasRecentlyExecuted(schedule, pastTime)) {
isMissedInRecentWindow = true;
log.warn("Found missed schedule execution for {} at {}",
schedule.getScheduleName(), pastTime);
break;
}
}
if (isCurrentMatched || isMissedInRecentWindow) {
executeBackupForSchedule(schedule);
}
}
}
4) 스케줄별 대상 인스턴스 관리 (ERD의 BACKUP_INSTANCE_TARGET 활용)
private void executeBackupForSchedule(JobBackupScheduleResponse schedule) {
// ERD에서 BACKUP_SCHEDULE ←1:N→ BACKUP_INSTANCE_TARGET 관계 활용
List<JobInstanceTargetResponse> targetInstances =
jobManager.retrieveInstanceTargetsByScheduleId(schedule.getJobId());
log.info("Found {} target instances for schedule {}",
targetInstances.size(), schedule.getScheduleName());
// 각 인스턴스별로 BACKUP_TASK 생성
for (JobInstanceTargetResponse targetInstance : targetInstances) {
ExecBackupTaskRequest request = new ExecBackupTaskRequest(
schedule.getProjectId(),
schedule.getJobId(),
targetInstance.getInstanceOpenstackId(),
schedule.getScheduleName() + ":" + targetInstance.getInstanceOpenstackId(),
schedule.getBackupType()
);
// Task Queue에 등록 (워크플로우 다이어그램의 TASK 단계)
executionService.triggerBackup(request);
}
}
큐/워커 기반 처리 아키텍처 (워크플로우 기반)
1) 계층적 작업 처리 (TASK → Volume Queue)
// 워크플로우 다이어그램의 TASK 처리 단계
public class BackupQueueWorker {
@PostConstruct
public void startWorker() {
executor.submit(() -> {
while (true) {
try {
// TASK Queue에서 인스턴스 백업 작업 수신
ExecBackupTaskRequest taskRequest = this.backupTaskQueue.take();
log.info("Processing backup task: {}", taskRequest.getTaskName());
// 1. Nova API로 인스턴스 정보 조회 (워크플로우의 Nova,Neutron,Cinder... 단계)
ExecBackupTask task = retrieveAndPersistInstance(taskRequest);
// 2. 인스턴스의 볼륨들을 Volume Queue에 등록
enqueueVolumeBackup(task);
// 3. 모든 볼륨 백업 완료까지 대기 후 Task 완료 처리
taskVolumeBackup();
executionService.doneInstanceBackup(taskRequest, task);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
} catch (Exception e) {
log.error("[BackupTaskQueue] 작업 처리 중 오류 발생", e);
}
}
});
}
}
2) 볼륨별 직렬 처리 (Volume Queue → Cinder)
// 워크플로우의 Volume Queue → Cinder API 단계
public void taskVolumeBackup() throws InterruptedException {
ExecVolumeBackupTaskRequest task = volumeBackupTaskQueue.take();
String projectOpenstackId = task.getProjectOpenstackId();
String volumeOpenstackId = task.getVolumeOpenstackId();
BackupType backupType = task.getBackupType();
try {
log.info("Starting volume backup: {} ({})", volumeOpenstackId, backupType);
// Cinder API 호출하여 백업 시작 (워크플로우의 Cinder 단계)
OSVolumeBackupCreateResponse backupResponse = openstackExecutor.backupVolume(
projectOpenstackId,
volumeOpenstackId,
backupType,
task.getSequenceNumber()
);
String backupVolumeOpenstackId = backupResponse.getId();
// 백업 상태를 주기적으로 폴링하여 완료까지 대기
monitorBackupProgress(projectOpenstackId, backupVolumeOpenstackId);
} catch (VolumesBadRequestException e) {
// 증분 백업 불가능한 경우 자동으로 Full 백업으로 폴백
handleIncrementalBackupFallback(e, task);
}
}
증분 백업 체인 관리 (워크플로우의 Full → Incremental1 → Incremental2)
1) 체인 부트스트랩과 자동 폴백
private void handleIncrementalBackupFallback(VolumesBadRequestException e,
ExecVolumeBackupTaskRequest task) throws Exception {
if (e.getError().getReason() != null &&
e.getError().getReason().contains("No backups available to do an incremental backup")) {
log.warn("Incremental backup not available for volume {}, falling back to FULL backup",
task.getVolumeOpenstackId());
// 워크플로우에서 체인이 없을 때 자동으로 Full 백업으로 전환하여 체인 시작
OSVolumeBackupCreateResponse fallbackResponse = openstackExecutor.backupVolume(
task.getProjectOpenstackId(),
task.getVolumeOpenstackId(),
BackupType.FULL, // 강제로 Full 백업
0L // 시퀀스 번호 0으로 초기화
);
// Full 백업 상태 모니터링
monitorBackupProgress(task.getProjectOpenstackId(), fallbackResponse.getId());
log.info("Successfully created fallback FULL backup {} for volume {}",
fallbackResponse.getId(), task.getVolumeOpenstackId());
} else {
throw e;
}
}
2) 백업 네이밍 규약과 체인 추적
public class BackupOpenstackExecutor {
// 백업 이름 생성: 원볼륨ID::백업타입::시퀀스::타임스탬프
private String generateBackupName(String volumeOpenstackId, BackupType backupType, Long sequenceNumber) {
StringBuilder volumeBackupOpenstackName = new StringBuilder();
String formattedNow = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyyMMddHHmmss"));
volumeBackupOpenstackName.append(volumeOpenstackId);
if (backupType.equals(BackupType.INCREMENTAL)) {
// 워크플로우의 Incremental1, Incremental2 네이밍
volumeBackupOpenstackName
.append("::")
.append(BackupType.INCREMENTAL)
.append("::")
.append(sequenceNumber)
.append("::")
.append(formattedNow);
} else if (backupType.equals(BackupType.FULL)) {
if (sequenceNumber > 0L) {
// 체인 중간의 Full 백업 (증분 실패 후 생성된 경우)
volumeBackupOpenstackName
.append("::")
.append(BackupType.FULL)
.append("::")
.append(sequenceNumber)
.append("::")
.append(formattedNow);
} else {
// 워크플로우의 최초 Full 백업
volumeBackupOpenstackName
.append("::")
.append(BackupType.FULL)
.append("::")
.append(formattedNow);
}
}
return volumeBackupOpenstackName.toString();
}
}
복구 시스템 (복구 워크플로우 기반)
1) 완전한 인스턴스 복구 재현성
// 복구 워크플로우: TASK+INSTANCE+VOLUME → Volume Restore → Nova Instance Create
public class RestoreQueueWorker {
public void processInstanceRestore(ExecRestoreTaskRequest request) {
// 1. ERD에서 BACKUP_TASK와 연관된 BACKUP_INSTANCE, BACKUP_VOLUME 조회
ExecBackupTask originalTask = backupTaskRepository.findById(request.getBackupTaskId());
List<ExecBackupInstance> backupInstances = originalTask.getBackupInstances();
for (ExecBackupInstance backupInstance : backupInstances) {
// 2. 각 볼륨별로 복구 작업을 Volume Restore Queue에 등록
List<ExecBackupVolume> backupVolumes = backupInstance.getBackupVolumes();
for (ExecBackupVolume backupVolume : backupVolumes) {
ExecVolumeRestoreRequest volumeRestoreRequest = new ExecVolumeRestoreRequest(
request.getProjectId(),
backupVolume.getBackupVolumeOpenstackId(),
backupVolume.getVolumeOpenstackId()
);
// 복구 워크플로우의 Volume Restore Queue 단계
volumeRestoreQueue.offer(volumeRestoreRequest);
}
// 3. 모든 볼륨 복구 완료 후 Nova로 인스턴스 재생성
waitForVolumeRestoreCompletion(backupVolumes);
recreateInstanceWithRestoredVolumes(backupInstance, request);
}
}
// 복구 워크플로우의 Nova Instance Create 단계
private void recreateInstanceWithRestoredVolumes(ExecBackupInstance backupInstance,
ExecRestoreTaskRequest request) {
// 원본 인스턴스의 메타데이터 복원 (Flavor, Network, Security Group)
OSInstanceCreateRequest instanceRequest = OSInstanceCreateRequest.builder()
.name(generateRestoreInstanceName(backupInstance))
.flavorId(backupInstance.getFlavorOpenstackId())
.imageId(backupInstance.getImageOpenstackId())
.networkId(backupInstance.getNetworkOpenstackId())
.securityGroups(parseSecurityGroups(backupInstance.getSecurityGroupOpenstackIds()))
.blockDeviceMappings(buildBlockDeviceMappings(backupInstance.getBackupVolumes()))
.build();
// Nova API로 인스턴스 생성 (복구 워크플로우의 Nova 단계)
OSInstanceCreateResponse response = novaAdapter.createInstance(
authService.getToken(request.getProjectId()),
request.getProjectId(),
instanceRequest
);
log.info("Instance recreated from backup: {} -> {}",
backupInstance.getInstanceOpenstackId(), response.getId());
}
}
2) 복구용 볼륨 이름 생성 (추적성 확보)
// 복구 네이밍: 원볼륨ID->백업ID::백업타입::시퀀스::백업시각
private String generateRestoreVolumeName(VolumeRestoreRequest restoreRequest) {
StringBuilder volumeOpenstackName = new StringBuilder(restoreRequest.getVolumeOpenstackId());
String backupVolumeOpenstackId = restoreRequest.getBackupVolumeOpenstackId();
// 백업 정보에서 메타데이터 추출
OSVolumeBackupRetrieveResponse backupInfo = retrieveBackupVolume(
restoreRequest.getProjectOpenstackId(),
backupVolumeOpenstackId
);
volumeOpenstackName.append("->").append(backupVolumeOpenstackId);
// 원본 백업 이름에서 체인 정보 추출하여 복구 볼륨 이름에 포함
String originalBackupName = backupInfo.getName();
if (originalBackupName.contains("::")) {
String[] nameParts = originalBackupName.split("::");
if (nameParts.length >= 3) {
// 백업타입::시퀀스::타임스탬프 정보 추가
volumeOpenstackName.append("::").append(nameParts[1]); // 백업 타입
if (nameParts.length == 4) {
volumeOpenstackName.append("::").append(nameParts[2]); // 시퀀스
volumeOpenstackName.append("::").append(nameParts[3]); // 백업 시각
} else {
volumeOpenstackName.append("::").append(nameParts[2]); // 백업 시각
}
}
}
return volumeOpenstackName.toString();
}
상태 폴링과 안정성
1) 정밀한 백업 상태 모니터링
private static final int VOLUME_STATUS_RETRIEVE_DELAY = 30000; // 30초 간격
private static final int MAX_POLLING_ATTEMPTS = 120; // 최대 1시간 대기
private void monitorBackupProgress(String projectOpenstackId, String backupVolumeOpenstackId)
throws InterruptedException {
int attempts = 0;
while (attempts < MAX_POLLING_ATTEMPTS) {
Thread.sleep(VOLUME_STATUS_RETRIEVE_DELAY);
attempts++;
ExecVolumeBackup openstackResponse = openstackExecutor.retrieveBackupVolume(
projectOpenstackId, backupVolumeOpenstackId
);
VolumeBackupStatus status = openstackResponse.getStatus();
if (status == VolumeBackupStatus.AVAILABLE) {
log.info("Backup {} completed successfully after {} attempts",
backupVolumeOpenstackId, attempts);
return;
}
if (status == VolumeBackupStatus.ERROR) {
log.error("Backup {} failed with ERROR status", backupVolumeOpenstackId);
throw new BackupFailedException("Backup failed with ERROR status");
}
if (status != VolumeBackupStatus.CREATING) {
log.error("Backup {} unexpected status: {}", backupVolumeOpenstackId, status);
throw new BackupFailedException("Unexpected backup status: " + status);
}
if (attempts % 10 == 0) { // 5분마다 진행상황 로깅
log.info("Backup {} still in progress... ({}/{})",
backupVolumeOpenstackId, attempts, MAX_POLLING_ATTEMPTS);
}
}
// 타임아웃 발생
log.error("Backup {} polling timeout after {} minutes",
backupVolumeOpenstackId, (MAX_POLLING_ATTEMPTS * VOLUME_STATUS_RETRIEVE_DELAY) / 60000);
throw new BackupTimeoutException("Backup polling timeout");
}
2) 보관 정책과 자동 정리 (ERD 기반)
@Scheduled(cron = "0 0 * * * *") // 매시간 정각 실행
public void executeBackupRetentionExpiryDeleteScheduler() {
log.info("Executing Backup Retention Expiry Delete Scheduler");
// ERD의 JOB → BACKUP_SCHEDULE 관계를 활용하여 Job 단위로 정리
jobManager.purgeRetentionExpiredBackups();
}
// ERD 구조를 따른 계층적 삭제
public void purgeRetentionExpiredBackups() {
List<JobBackupScheduleResponse> schedules = retrieveAllSchedules();
for (JobBackupScheduleResponse schedule : schedules) {
Integer retentionDays = schedule.getRetentionDays();
if (retentionDays == null) continue;
LocalDateTime cutoffDate = LocalDateTime.now().minusDays(retentionDays);
// ERD: BACKUP_TASK → BACKUP_INSTANCE → BACKUP_VOLUME 순으로 만료 검사
List<ExecBackupTask> expiredTasks = findExpiredBackupTasks(schedule.getJobId(), cutoffDate);
deleteBackupsInSafeOrder(expiredTasks);
}
}
운영 성과와 학습
정량적 성과
- RPO 향상: 증분 우선 정책 + 자동 Full 폴백으로 백업 체인 항상 유효
- RTO 단축: 네이밍 규약으로 복구 대상 백업 즉시 식별, 완전한 인스턴스 재현
- 비용 절감: 증분 백업 우선으로 장기 보관 시 스토리지 효율성 극대화
- 안정성: 스케줄 누락 보정 + 상태 폴링으로 백업 실패 최소화
아키텍처 설계의 핵심 가치
- ERD 기반 정규화: Job → Schedule → Target → Task → Instance → Volume의 계층적 관리
- 워크플로우 시각화: 복잡한 백업/복구 프로세스의 단계별 명확한 정의
- 큐 기반 확장성: 단일 워커에서 다중 워커로 수평 확장 용이한 설계
- 메타데이터 보존: 인스턴스의 Flavor, Network, SecurityGroup까지 완전 복구 가능
기술적 학습 효과
- Cinder API 마스터: 백업 생명주기, 상태 전이, 의존성 관리의 깊이 있는 이해
- 분산 시스템 설계: Queue/Worker 패턴을 통한 확장 가능하고 안정적인 아키텍처 구현
- 운영 중심 설계: 스케줄 드리프트, 시스템 지연 등 현실적 운영 이슈 해결 역량
- 데이터 모델링: 복잡한 백업/복구 도메인을 ERD로 체계적 설계하는 능력